

Voice Activity Detection, often shortened to VAD, is a technology used to determine whether an audio signal contains human speech or non-speech content such as silence, background noise, music, keyboard sounds, breathing, or environmental interference. It is widely used in VoIP systems, AI voice assistants, speech recognition, conference platforms, call recording, two-way radios, mobile apps, and embedded communication devices.
What Voice Activity Detection Means in Audio Systems
In a real-time audio system, the microphone is constantly receiving sound. Not every sound should be transmitted, recorded, processed, or sent to a speech recognition engine. Voice Activity Detection helps the system decide when a person is actually speaking and when the audio stream can be treated as silence or background noise.
This decision may look simple, but it is technically important. A poor VAD system may cut off the beginning or end of speech, send too much noise to the server, create false triggers, or make users feel that the system is slow. A well-designed VAD system improves speech quality, saves bandwidth, reduces computing cost, and makes voice interaction feel more natural.

How Voice Activity Detection Works
Audio Signal Analysis
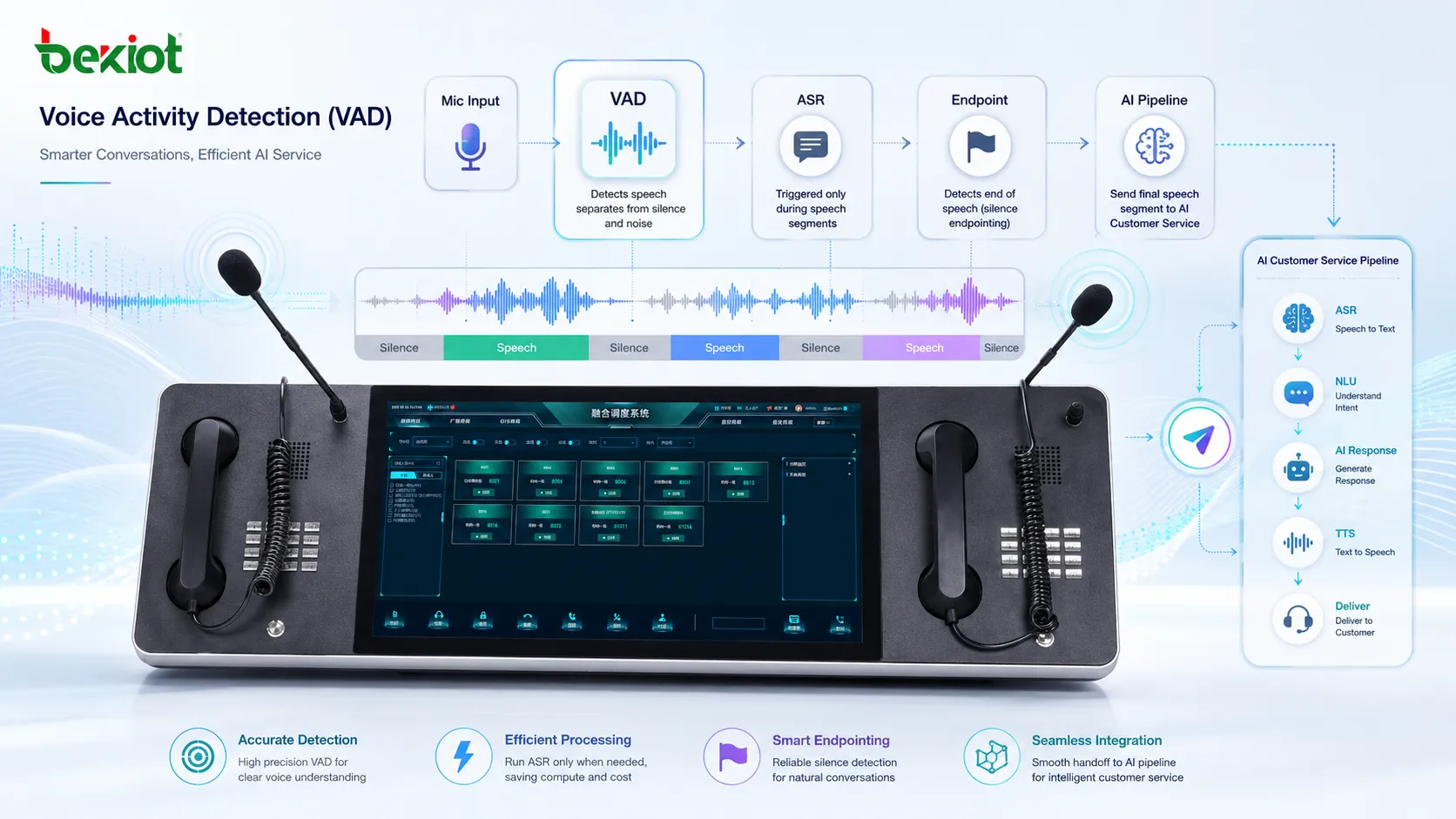
VAD starts by analyzing short frames of audio. These frames are usually measured in milliseconds, allowing the system to make fast decisions without waiting for a long recording. Each frame may be checked for energy level, frequency distribution, signal variation, zero-crossing rate, spectral features, or machine-learning-based speech probability.
Traditional VAD methods often rely on acoustic thresholds. For example, if the audio energy is higher than a noise floor, the system may consider it speech. Modern VAD systems may use neural networks or statistical models to distinguish speech from noise more accurately, especially in environments with fans, traffic, machinery, music, or multiple speakers.
Speech and Silence Decision
After analyzing the audio frame, the VAD engine makes a decision: speech, silence, or sometimes uncertain. In practical systems, this decision is usually smoothed over time. Without smoothing, the result may switch too quickly between speech and silence, causing unnatural audio cutting.
Most real deployments use parameters such as start threshold, end threshold, minimum speech duration, silence timeout, and hangover time. Hangover time means the system continues treating the audio as speech for a short period after detected speech energy drops. This helps prevent the last syllable of a sentence from being cut off too early.
Integration with Voice Processing
VAD is rarely used alone. It often works with noise suppression, echo cancellation, automatic gain control, speech recognition, wake word detection, call recording, audio compression, and real-time communication protocols. In an AI voice system, VAD may decide when to start streaming audio to ASR and when to stop listening for the user’s sentence.
In a VoIP or conferencing system, VAD may reduce packet transmission during silence. In recording systems, it may mark active speech segments for easier playback and search. In embedded devices, it may reduce CPU usage and battery consumption by avoiding unnecessary audio processing.
Main Features of Voice Activity Detection
Real-Time Speech Detection
The most important feature of VAD is real-time detection. The system must recognize speech quickly enough to support natural communication. If the delay is too long, users may experience slow response, interrupted conversation, or delayed AI interaction.
Real-time VAD is especially important for voice assistants, AI customer service, dispatch communication, push-to-talk systems, video conferencing, and hands-free intercoms. These scenarios require fast speech start detection and stable silence detection at the end of a phrase.
Noise Robustness
Real-world audio environments are rarely quiet. A VAD system may need to work in offices, factories, vehicles, streets, hospitals, schools, warehouses, call centers, control rooms, or outdoor sites. Background noise can make speech detection difficult, especially when the noise level changes over time.
Noise-robust VAD can adapt to changing sound conditions and reduce false triggers. For example, it should not treat keyboard typing, air conditioning, short impacts, or distant conversations as the main speaker’s voice. This improves accuracy and reduces unnecessary audio transmission.
| VAD Capability | What It Does | Why It Matters |
|---|---|---|
| Speech start detection | Identifies when a user begins speaking | Helps systems respond quickly and avoid missing the first words |
| Silence endpointing | Detects when speech has ended | Allows ASR, recording, or AI response logic to stop at the right time |
| Noise filtering | Reduces false detection from background sounds | Improves accuracy in real-world environments |
| Hangover control | Keeps speech active briefly after the signal drops | Prevents the end of words or sentences from being clipped |
| Frame-level analysis | Processes short audio segments continuously | Supports real-time decision-making with low latency |
Configurable Sensitivity
Different applications need different VAD sensitivity. A quiet office voice assistant may use a relatively sensitive setting, while an industrial intercom may need stronger filtering to avoid false activation from machines. Sensitivity tuning helps balance missed speech and false detection.
Common configuration items include audio energy threshold, minimum speech length, maximum silence duration, end-of-speech delay, noise floor adaptation, and confidence score. These settings should be adjusted according to microphone distance, background noise, user speaking style, and system response requirements.
Why Voice Activity Detection Matters
Better User Experience
In voice interaction, timing is critical. If the system starts listening too late, it may miss the first word. If it stops too early, it may cut off the user. If it waits too long after the user finishes, the system feels slow. VAD helps create smoother turn-taking between humans and machines.
This is especially important in AI customer service, smart assistants, voice search, dictation tools, and hands-free control. Users expect the system to understand when they are speaking without pressing buttons or manually starting and stopping recording.
Lower Bandwidth and Processing Cost
Audio transmission and processing consume network bandwidth, server resources, and device power. By sending or processing only speech-active segments, VAD can reduce unnecessary workload. This is useful for large-scale voice platforms, cloud ASR services, conference systems, and mobile applications.
In edge devices, VAD can also help reduce power consumption. The device may keep high-cost processing modules inactive until speech is detected, which is valuable for battery-powered products and embedded voice terminals.
Cleaner Recording and Easier Review
In recording systems, VAD can help separate useful speech from long periods of silence. This makes audio archives easier to review and reduces storage waste. For call centers, meetings, interviews, dispatch rooms, and compliance recording, speech segmentation can improve search and playback efficiency.
Some systems use VAD markers to highlight active speaking sections on a timeline. Reviewers can jump directly to voice segments instead of listening through long silent intervals.
Common Applications
Automatic Speech Recognition
ASR systems use VAD to decide which part of an audio stream should be recognized as speech. Without VAD, the ASR engine may receive too much silence or noise, increasing processing cost and reducing recognition stability.
In conversational AI, VAD is also used for endpoint detection. When the system detects that the user has stopped speaking, it can send the completed utterance to the language model or dialogue engine. Good endpointing makes the conversation feel faster and more natural.
VoIP and Video Conferencing
VoIP phones, softphones, conferencing platforms, and WebRTC applications may use VAD to optimize audio transmission. During silence, the system can reduce packet sending or mark the stream as inactive. This helps reduce network usage, especially in large meetings or low-bandwidth environments.
VAD may also support active speaker detection in video meetings. When the system knows who is speaking, it can highlight the active speaker, adjust layout, or improve audio mixing behavior.
Call Centers and Quality Monitoring
Call centers use VAD to analyze agent and customer speech patterns. It can help identify silence periods, interruptions, long pauses, talk-over events, and response delay. These insights can support service quality review, script optimization, and agent training.
When combined with speech analytics, VAD can also help segment conversations before transcription, keyword detection, sentiment analysis, or compliance checks.
Radio, Intercom, and Push-to-Talk Systems
In radio and intercom communication, VAD can help control audio activation, reduce open-channel noise, and improve hands-free operation. It may be used in dispatch systems, industrial intercoms, transportation communication, security rooms, and emergency response networks.
However, these environments often contain strong background noise. VAD settings must be tuned carefully to avoid false activation from sirens, engines, alarms, machinery, wind, or other non-speech sounds.
Deployment Considerations
Microphone Quality and Placement
VAD performance depends heavily on audio input quality. A good algorithm may still perform poorly if the microphone is too far from the speaker, exposed to wind, placed near a noise source, or affected by echo. Microphone selection and placement should be considered part of the VAD design.
Directional microphones, acoustic shielding, echo cancellation, and noise suppression can improve detection quality. In conference rooms and industrial sites, microphone layout may be just as important as software configuration.
Latency and Endpoint Timing
Low latency is important, but cutting speech too aggressively can damage user experience. Systems must balance fast response with complete speech capture. For example, an AI assistant may need a short silence timeout to respond quickly, while dictation software may need a longer timeout to allow natural pauses.
Endpoint timing should match the application. A command phrase, a customer service conversation, a meeting transcript, and a radio dispatch message may each require different silence duration settings.
Testing in Real Acoustic Conditions
VAD should be tested with realistic audio instead of only clean lab recordings. Field testing should include different speakers, accents, speech speeds, microphone distances, background noise levels, echo conditions, and network states.
Testing should also check edge cases such as short answers, whispered speech, overlapping speakers, sudden noise, long pauses, and speech after silence. These cases often reveal whether the VAD configuration is suitable for production use.

Conclusion
Voice Activity Detection is a foundational technology for modern voice systems. It helps identify when speech starts, when speech ends, and which parts of an audio stream should be transmitted, recorded, or processed. Although it works behind the scenes, it has a direct impact on user experience, bandwidth efficiency, ASR accuracy, recording quality, and real-time communication performance.
A successful VAD deployment requires more than enabling a single function. It should consider microphone quality, acoustic environment, sensitivity settings, latency targets, endpoint timing, noise suppression, and application workflow. When properly designed and tested, VAD makes voice systems faster, cleaner, more efficient, and more natural to use.
FAQ
Is Voice Activity Detection the same as wake word detection?
No. VAD detects whether speech is present, while wake word detection looks for a specific phrase such as a device name or activation command. A system may use VAD before wake word detection to reduce unnecessary processing, but the two functions are not the same.
Can VAD understand what a person is saying?
No. VAD does not recognize words or meaning. It only decides whether the audio likely contains speech. Speech recognition or natural language processing is required to convert spoken words into text and understand user intent.
Why does a VAD system sometimes stop before the user finishes speaking?
This usually happens when the silence timeout is too short, the user pauses between words, the microphone level is low, or the background noise causes unstable detection. Adjusting endpoint delay, gain level, and hangover settings can reduce this problem.
Does VAD work well with multiple people speaking at the same time?
VAD can detect that speech exists, but it does not automatically separate speakers. In multi-speaker environments, speaker diarization, beamforming, or audio source separation may be needed to identify who is speaking.
Should VAD run on the device or in the cloud?
Both options are possible. Device-side VAD can reduce bandwidth, improve privacy, and lower cloud processing cost. Cloud-side VAD may offer stronger models and easier updates. The best choice depends on latency, privacy, hardware capability, and system architecture.







