

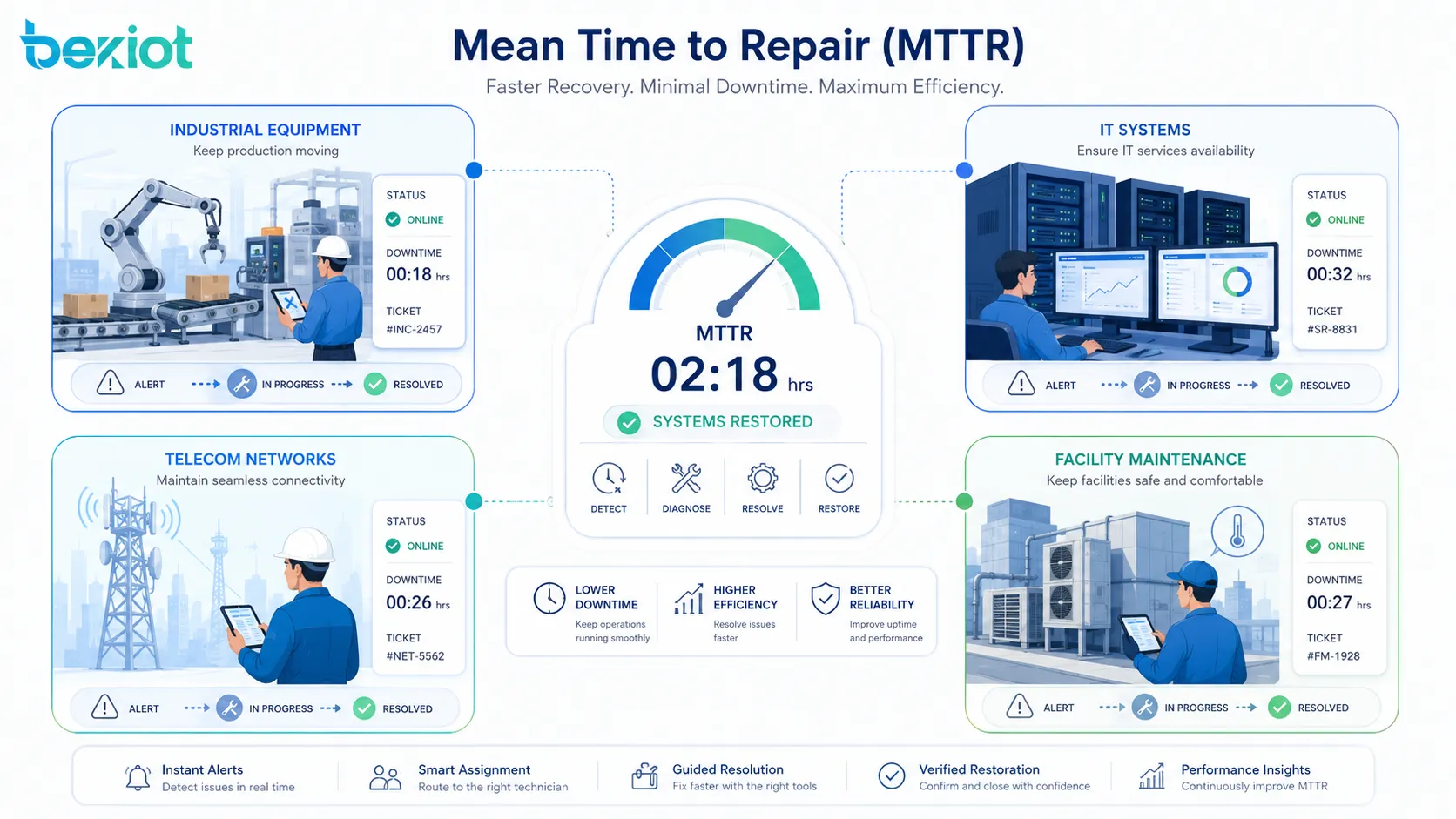
Mean Time to Repair, commonly abbreviated as MTTR, is a maintenance and reliability metric that measures the average time required to restore a failed asset, device, machine, software service, network component, or production system back to normal operation. It focuses on the repair process after a failure has occurred, making it an important indicator for downtime control, service efficiency, operational resilience, and maintenance planning.
In factories, data centers, telecom networks, transportation systems, power facilities, hospitals, buildings, and IT environments, failures cannot always be avoided. What matters is how quickly the organization can detect the problem, diagnose the cause, complete the repair, test the result, and return the system to service. MTTR helps teams understand that recovery performance in a measurable way.
Basic Meaning in Reliability Management
Mean Time to Repair represents the average repair duration across multiple failure events. It is not the time between failures, and it is not the total downtime of an entire system over a long period. Instead, it answers a practical question: when something fails, how long does it usually take to fix it?
The metric is widely used by maintenance engineers, facility managers, IT service teams, reliability engineers, equipment manufacturers, and operations managers. A lower MTTR usually means faster restoration, better maintenance response, improved spare parts readiness, clearer procedures, and more effective troubleshooting.
What MTTR Actually Measures
MTTR usually includes the active repair time needed to bring an asset back to working condition. Depending on how an organization defines the metric, it may include fault confirmation, diagnosis, spare parts replacement, configuration recovery, functional testing, and final service restoration.
For example, if a production machine stops because of a faulty sensor, the repair time may include technician dispatch, sensor inspection, replacement, calibration, and restart verification. If a server fails, the repair time may include incident analysis, component replacement, data recovery, rebooting, and service validation.
Why the Definition Must Be Clear
Different organizations may calculate MTTR in slightly different ways. Some teams count from the moment a fault is reported. Others count from the time repair work begins. Some include waiting time for spare parts, while others only include hands-on technical repair time.
This is why MTTR should be clearly defined before it is used for performance comparison. Without a consistent definition, the metric can become misleading. A maintenance team may appear slow simply because its calculation includes waiting time, approval time, or travel time, while another team only measures actual repair activity.
How the Calculation Works
The standard MTTR formula is simple. Add the repair time for all repair events during a specific period, then divide that number by the total number of repair events. The result shows the average time needed to restore the failed asset or system.
For example, if five repairs take 2 hours, 3 hours, 1 hour, 4 hours, and 5 hours, the total repair time is 15 hours. Dividing 15 hours by five repair events gives an MTTR of 3 hours. This means each repair takes 3 hours on average.
Repair Time Collection
Accurate MTTR depends on accurate repair records. Teams need to record when a failure is detected, when repair starts, what actions are taken, when service is restored, and whether the repair is verified. Maintenance management systems, ticketing platforms, SCADA logs, service desks, and computerized maintenance management systems can all help collect this information.
Manual records can also work, but they must be consistent. If technicians forget to close work orders, record incomplete repair times, or classify incidents differently, the final MTTR value may not reflect real operational performance.
Simple Example for Equipment Repair
Imagine a facility has a ventilation unit that fails three times in one month. The first repair takes 90 minutes, the second repair takes 120 minutes, and the third repair takes 60 minutes. The total repair time is 270 minutes.
Using the MTTR formula, 270 minutes divided by 3 repair events equals 90 minutes. The MTTR for that ventilation unit is therefore 90 minutes. Facility managers can use this number to evaluate response efficiency, technician workload, spare parts availability, and the need for preventive maintenance.
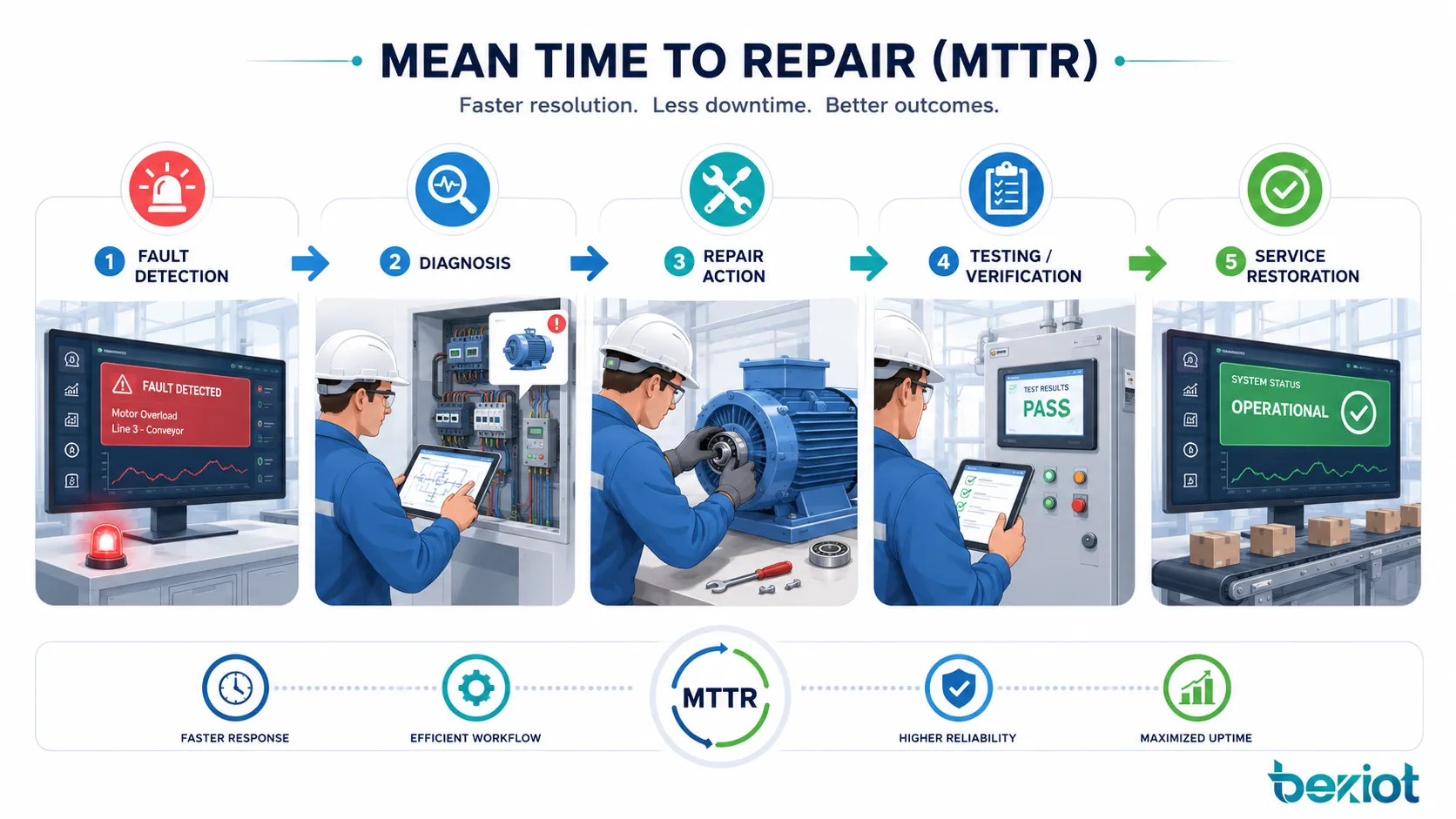
What Happens During a Repair Cycle
MTTR is not only a mathematical average. It reflects the complete repair workflow behind each failure. A long repair time may come from slow fault detection, unclear troubleshooting steps, unavailable spare parts, poor documentation, difficult equipment access, or lack of trained personnel.
Understanding the repair cycle helps teams improve the real causes of downtime instead of only looking at the final number.
Failure Detection and Reporting
The repair cycle starts when a failure is detected. In some systems, detection is automatic through alarms, sensors, monitoring dashboards, self-diagnostics, or fault codes. In other cases, an operator, user, or technician notices the problem and reports it manually.
Fast detection can reduce the overall impact of a failure. If a machine fault is discovered immediately, repair can begin before the problem spreads to production quality, safety, or downstream equipment. In IT and network operations, automatic alerts can shorten incident response time significantly.
Diagnosis and Root Cause Identification
After detection, technicians or engineers must identify the cause. Diagnosis may involve visual inspection, log analysis, electrical testing, mechanical checking, software review, network tracing, or comparison with historical failure records.
Diagnosis is often one of the most important factors affecting MTTR. A team with good documentation, clear fault codes, remote monitoring, and experienced technicians can identify problems faster than a team that relies only on trial and error.
Repair, Replacement, and Verification
The actual repair may involve component replacement, software restart, configuration correction, cable repair, mechanical adjustment, firmware recovery, cleaning, lubrication, recalibration, or full equipment replacement.
After the repair is completed, the system should be tested before it is returned to normal use. Verification may include startup testing, safety checks, production trial runs, network connectivity tests, alarm reset confirmation, or user acceptance. Without verification, a system may appear repaired but fail again shortly afterward.
Why This Metric Matters
MTTR matters because downtime has real consequences. It can stop production, delay service delivery, reduce customer satisfaction, increase operating costs, create safety risks, and disrupt business continuity. By tracking repair time, organizations can identify weak points in maintenance and improve recovery performance.
MTTR is most useful when it leads to action. The goal is not only to calculate average repair time, but to understand why repairs take that long and how the process can be improved.
Reducing Downtime Impact
A lower MTTR means equipment or systems return to operation faster after failure. In manufacturing, this can reduce production loss. In telecom and IT environments, it can reduce service interruption. In buildings and infrastructure, it can improve comfort, safety, and service availability.
Downtime reduction is especially important for mission-critical systems. Emergency communication platforms, power distribution equipment, medical systems, traffic control infrastructure, security systems, and industrial production lines often require rapid restoration because service interruption can create serious operational consequences.
Improving Maintenance Efficiency
MTTR gives maintenance teams a way to evaluate how efficiently they respond to problems. If the average repair time is increasing, managers can investigate whether the issue is caused by spare parts delays, insufficient training, poor access to equipment, slow escalation, or unclear repair instructions.
By comparing MTTR across equipment types, locations, shifts, or service teams, organizations can identify where improvements are most needed. This can support better staffing, more focused training, improved documentation, and smarter spare parts planning.
Supporting Reliability and Availability Goals
System availability depends on both failure frequency and recovery speed. Even if equipment fails occasionally, fast repair can help maintain acceptable service availability. MTTR is therefore often used together with Mean Time Between Failures, uptime percentage, service-level objectives, and reliability targets.
For example, a system with frequent failures and long repair times will have poor availability. A system with rare failures and short repair times will usually perform much better from an operational continuity perspective.
Benefits for Operations and Maintenance Teams
MTTR provides practical value because it links technical maintenance performance with business outcomes. It helps teams move from reactive repair to structured improvement. Instead of discussing downtime in general terms, managers can use repair-time data to make decisions.
Better Spare Parts Planning
If repairs take too long because spare parts are unavailable, MTTR data can expose the problem. Maintenance teams can then identify critical components, set minimum stock levels, improve supplier agreements, or use replacement modules for faster recovery.
For high-value or safety-related assets, the cost of keeping spare parts in stock may be much lower than the cost of extended downtime. MTTR analysis helps justify that decision with measurable evidence.
Clearer Service-Level Management
In outsourced maintenance, IT support, telecom services, and facility operations, MTTR can support service-level agreements. It gives both service providers and customers a measurable indicator for repair performance.
However, service-level targets should be realistic. A repair target for a simple access control reader is different from a target for a complex production line, large HVAC system, or multi-site network failure. Equipment complexity, location, risk level, and access conditions should all be considered.
More Effective Training and Documentation
High MTTR may show that technicians need better training or clearer repair instructions. If the same type of failure repeatedly takes too long to resolve, the organization can create standard troubleshooting guides, visual work instructions, diagnostic checklists, or remote support procedures.
Good documentation reduces dependency on individual experience. It also helps new technicians perform repairs more confidently and reduces the risk of repeated mistakes.
Common Applications Across Industries
Mean Time to Repair is used in many industries because almost every organization depends on assets, systems, devices, or services that can fail. The specific repair process may differ, but the need to measure and improve restoration time is universal.
Manufacturing and Industrial Equipment
In manufacturing plants, MTTR is used to measure repair performance for production lines, motors, pumps, conveyors, robots, CNC machines, packaging equipment, sensors, control cabinets, and utility systems.
Reducing MTTR in industrial environments can improve production continuity, reduce overtime, increase asset utilization, and support lean maintenance programs. It also helps maintenance teams identify which machines create the most repair burden.
IT Systems and Data Centers
In IT operations, MTTR may apply to servers, storage systems, applications, databases, cloud services, firewalls, switches, routers, and user-facing platforms. It is commonly used in incident management and site reliability engineering.
For digital services, repair may involve restoring software functionality rather than replacing physical components. The repair process may include log review, rollback, patching, failover, configuration correction, restart, or recovery from backup.
Telecom and Network Infrastructure
Telecom operators and enterprise network teams use MTTR to evaluate recovery speed for base stations, fiber links, transmission equipment, IP networks, communication gateways, routers, switches, and service platforms.
Network-related failures can affect many users at once. Fast repair and accurate fault localization are essential for maintaining service quality. Remote monitoring, redundant links, clear escalation paths, and field service coordination can all help reduce MTTR.
Facilities, Buildings, and Utilities
Facility managers use MTTR for HVAC systems, elevators, pumps, lighting control, access control, fire alarm interfaces, security equipment, power distribution, water systems, and building automation devices.
In buildings and utility environments, MTTR is closely connected to occupant comfort, safety, regulatory compliance, and service continuity. Long repair times can affect tenants, visitors, production areas, or public infrastructure users.
MTTR Compared with Related Metrics
MTTR is often discussed with other reliability and maintenance metrics. Understanding the difference helps teams choose the right indicator for the right purpose. MTTR focuses on repair speed, while other metrics may focus on failure frequency, service availability, or incident response time.
| Metric | Meaning | Main Purpose |
|---|---|---|
| MTTR | Mean Time to Repair | Measures average time needed to restore a failed asset or system |
| MTBF | Mean Time Between Failures | Measures average operating time between failures |
| MTTF | Mean Time to Failure | Estimates expected life before failure for non-repairable items |
| MTTA | Mean Time to Acknowledge | Measures how long it takes to notice and acknowledge an incident |
| Availability | Operational uptime ratio | Shows how often a system is available for use |
MTTR and MTBF
MTBF measures how often failures happen, while MTTR measures how quickly failures are repaired. Both are important. A system may have a high MTBF but still cause serious disruption if each repair takes a long time.
For example, a machine that fails only twice a year may still be a problem if each failure takes three days to repair. On the other hand, a less critical device may fail more often but be repaired in minutes. MTBF and MTTR should be reviewed together for a complete reliability view.
MTTR and Availability
Availability is strongly influenced by MTTR. If repair time decreases, availability can improve, assuming the failure rate remains the same. This is why reducing MTTR is a common strategy for systems that cannot be redesigned immediately to fail less often.
In practical terms, teams can improve availability by preventing failures, repairing faster, adding redundancy, improving monitoring, or designing systems that continue operating in degraded mode while repair is underway.
How to Reduce Repair Time
Reducing MTTR requires more than asking technicians to work faster. Sustainable improvement usually comes from better system design, better information, better preparation, and better coordination. The goal is to remove delays from the repair process.
Use Monitoring and Early Fault Detection
Automatic monitoring can detect abnormal conditions before they become major failures. Sensors, logs, alarms, dashboards, condition monitoring systems, and predictive maintenance tools can help teams respond earlier and diagnose problems more quickly.
Early detection is especially useful when equipment has warning signs such as vibration, temperature rise, pressure change, voltage fluctuation, error codes, or communication instability. Acting on these signals can reduce both repair time and failure impact.
Standardize Troubleshooting Procedures
Repair speed improves when technicians follow clear procedures. Troubleshooting checklists, fault trees, maintenance manuals, wiring diagrams, spare parts lists, software recovery steps, and escalation rules can all reduce uncertainty.
Standard procedures also make performance more consistent across different technicians and shifts. They help ensure that the same problem is handled in the same reliable way each time.
Improve Access to Spare Parts and Tools
Many repairs are delayed not because the fault is difficult, but because the required part, tool, password, software image, cable, or test instrument is not available. Preparing repair kits and stocking critical spares can significantly reduce restoration time.
For distributed sites, local spare parts, regional service centers, or modular replacement strategies can help avoid long travel and shipping delays. In digital systems, ready-to-use backups and configuration templates can serve a similar purpose.
Limits and Misuse of MTTR
Although MTTR is useful, it should not be treated as the only maintenance performance indicator. A low MTTR does not always mean the system is reliable. It may simply mean the team is good at fixing repeated failures. If the same asset keeps failing, the root problem still needs attention.
MTTR can also hide variation. An average value may look acceptable even when a few critical incidents take much longer than expected. For important systems, teams should review repair-time distribution, worst-case incidents, repeated failures, and high-risk equipment separately.
Do Not Ignore Failure Prevention
Repair speed is important, but preventing avoidable failures is usually better. Preventive maintenance, condition monitoring, design improvement, proper installation, operator training, and environmental protection can all reduce failure frequency.
A strong maintenance strategy should balance fast repair with long-term reliability improvement. MTTR tells teams how fast they recover, but it does not explain why failures happen in the first place unless it is combined with root cause analysis.
Do Not Compare Without Context
Comparing MTTR across different systems can be misleading. A simple sensor replacement is not comparable to a turbine repair, network outage, elevator fault, or database recovery. Each asset type has its own complexity, risk level, access condition, and repair requirement.
Meaningful comparison should be done within similar equipment groups, similar service conditions, or the same asset over time. This helps teams identify real improvement instead of creating unfair performance judgments.
Best Practices for Practical Use
To use MTTR effectively, organizations should define the metric clearly, collect reliable data, analyze the causes behind long repairs, and connect findings to improvement actions. The metric should support better decisions, not become a reporting number only.
Define Start and End Points
Every organization should decide when repair time begins and ends. It may begin when the failure is reported, when the ticket is opened, when the technician arrives, or when active repair starts. It may end when the asset restarts, when testing is complete, or when the user confirms service restoration.
The chosen definition should match the purpose of measurement. If the goal is customer service improvement, total downtime may be more relevant. If the goal is technician repair efficiency, active repair time may be more appropriate.
Segment the Data
Instead of calculating one broad MTTR for all assets, teams should segment data by equipment type, location, failure category, severity level, team, shift, supplier, or system function. This makes the metric more useful and actionable.
For example, a facility may discover that pump repairs are fast, but elevator repairs are slow because spare parts are outsourced. An IT team may find that application incidents are resolved quickly, while network incidents require longer diagnosis. Segmentation reveals where improvement should begin.
Connect MTTR with Root Cause Analysis
When repair times are high, teams should investigate the reason. Was the fault difficult to diagnose? Was documentation missing? Was the spare part unavailable? Was approval delayed? Was remote access unavailable? Was the equipment difficult to reach?
Root cause analysis turns MTTR from a passive measurement into an active improvement tool. Over time, this can reduce downtime, improve reliability, and make maintenance planning more predictable.
FAQ
What does Mean Time to Repair mean?
Mean Time to Repair is the average time required to restore a failed asset, system, device, or service to normal operation. It is calculated by dividing total repair time by the number of repair events during a defined period.
Is MTTR the same as downtime?
Not always. MTTR usually focuses on repair duration, while downtime may include detection time, reporting delay, waiting time, spare parts delay, approval time, and restart time. Organizations should define exactly what is included before using the metric.
What is a good MTTR value?
A good MTTR depends on the equipment, industry, service requirement, and failure severity. A few minutes may be expected for a digital service restart, while several hours may be reasonable for complex industrial equipment. The best benchmark is often comparison against similar assets or previous performance.
How can a company reduce MTTR?
A company can reduce MTTR by improving monitoring, speeding up fault detection, standardizing troubleshooting, training technicians, keeping critical spare parts available, using remote diagnostics, improving documentation, and simplifying equipment access.
Why is MTTR important for reliability?
MTTR is important because repair speed directly affects downtime and system availability. Even reliable systems can fail, so fast recovery helps reduce operational impact, service interruption, production loss, and customer dissatisfaction.
What is the difference between MTTR and MTBF?
MTTR measures how long repairs take after failure. MTBF measures the average time between failures. MTTR focuses on recovery speed, while MTBF focuses on failure frequency. Both metrics are useful for understanding overall reliability and availability.







