

Imagine a remote site losing its connection to the central platform while operators still need to call each other, reach emergency contacts, and keep essential communication running.
This is where Local Survivability becomes valuable. It is not designed for ideal network conditions. It is designed for the moment when the main path is interrupted, the wide-area link is unstable, the central server is unreachable, or the cloud service cannot be accessed from the site.
Keeping essential communication active during network isolation
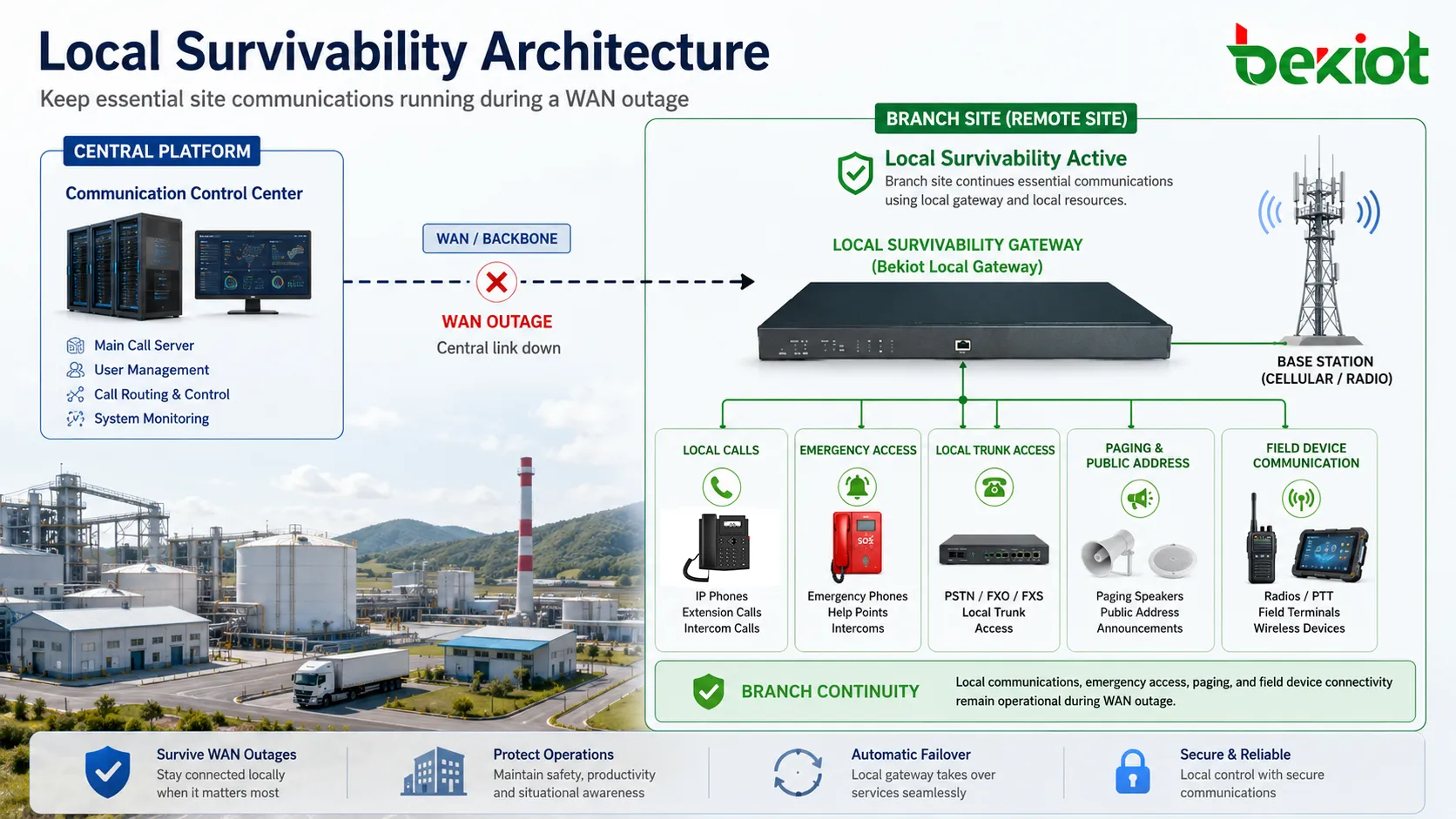
Local Survivability refers to the ability of a branch site, field station, industrial facility, or remote communication node to continue running core services even when its connection to the central system is interrupted. In communication networks, this usually means that local users can still call each other, access predefined emergency numbers, use local trunks, or maintain critical voice services without waiting for the central platform to recover.
The practical advantage is continuity. Many distributed systems depend on centralized servers for registration, routing, policy control, recording, or user management. This centralized model is efficient during normal operation, but it also creates dependency. If the WAN link fails, devices at the remote site may lose access to the main call server, cloud PBX, dispatch platform, or communication control center. Without survivability, the site may become operationally isolated.
With Local Survivability, a local gateway, server, controller, or embedded service node can temporarily take over selected communication functions. It does not necessarily replace the central platform completely. Instead, it preserves the services that matter most for local operation: internal calls, emergency communication, local routing, failover trunks, device registration fallback, and sometimes limited dispatch or announcement functions.
This capability is especially important in industrial plants, transportation stations, energy facilities, campuses, logistics parks, mines, tunnels, airports, and public service sites. These environments may not be able to stop communication simply because a backbone link is down. Local Survivability gives the site a controlled fallback state rather than a complete service outage.
Reducing dependence on a single central platform
Centralized communication platforms simplify management, but they can become a single point of dependency if remote sites have no local fallback. In a normal architecture, endpoint registration, call routing, authentication, number translation, and service policies may all be handled by the central system. If every communication action must travel through that platform, a link failure can affect even simple local calls between two devices in the same building.
Local Survivability changes this dependency model. It allows selected local functions to remain available under predefined conditions. For example, local extensions may re-register to a survivable gateway, or the gateway may preserve a cached dial plan for local calls. Emergency numbers can be routed through local trunks. Security offices, maintenance teams, production control rooms, and field terminals can continue to communicate inside the site even if the main server is unreachable.
This does not mean decentralizing everything. A good design still uses centralized management during normal operation because it offers unified configuration, monitoring, policy control, and easier maintenance. Survivability adds a second operating state. The system works centrally when the network is healthy and shifts to local control only when the central path fails.
The advantage is balance. Organizations can benefit from centralized architecture without accepting total service loss during network isolation. This is particularly valuable for multi-site deployments where each branch, station, plant, or field node has its own operational responsibilities.
Maintaining emergency calling when the main route fails
Emergency calling is one of the most important reasons to deploy Local Survivability. In many environments, users may need to contact security, fire response, medical support, control room operators, or local emergency services during exactly the kind of incident that also disrupts network connectivity. If the communication system depends entirely on a central platform, emergency calling may fail when it is most needed.
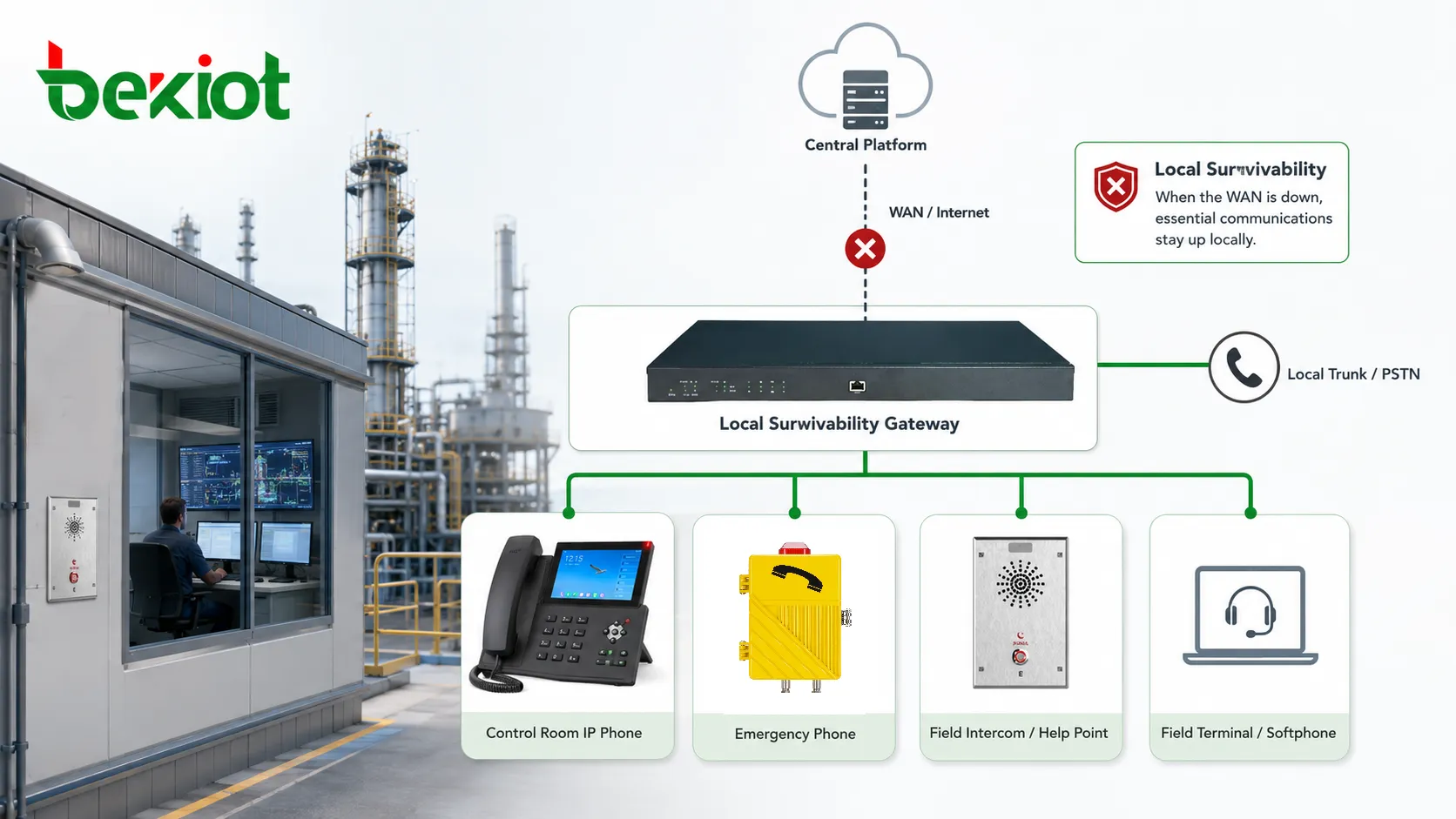
A survivable local node can preserve emergency call routing through local numbers, analog lines, SIP trunks, radio gateways, or predefined response terminals. The design depends on the site, but the principle is the same: emergency communication should have a local path that does not rely completely on distant infrastructure. This is especially important for remote industrial sites, transport stations, underground facilities, offshore platforms, and public safety environments.
Local Survivability also helps with predictable emergency behavior. When the central platform is down, users should not have to guess which numbers still work. The system should define which emergency numbers remain available, where those calls are routed, how operators are alerted, and whether fallback routing is automatic. Clear behavior under failure conditions is more valuable than a complex system that works only under normal conditions.
For deployment planning, emergency routing should be tested separately from ordinary calling. Engineers should confirm whether emergency calls still connect during simulated WAN failure, whether caller location or device identity is preserved where required, whether local operators receive the call, and whether backup trunks function correctly. Survivability is only meaningful if the fallback path has been verified before a real incident occurs.
Supporting local operations in industrial and remote sites
Some sites cannot pause operations just because the central network becomes unavailable. A production line may still need coordination between control room and field staff. A railway station may still need internal communication between platform, security, and maintenance. A mine may still need voice contact between underground points and local supervision. A power substation may still need communication between operators and field technicians. These are local workflows, and many of them should remain available even during central disconnection.
Local Survivability supports this by keeping communication close to the people and devices that need it. Instead of routing every call through a remote data center or cloud platform, selected local calls can be handled within the site. This reduces dependency on long network paths and gives the facility a basic operating capability during degraded conditions.
In industrial environments, the value is not only technical continuity. It also supports safety and production discipline. Operators can still report faults, maintenance teams can still coordinate repair, security staff can still communicate with gates or patrol points, and emergency phones can still reach local response positions. The site may operate in a reduced mode, but it does not become silent.
This is particularly useful in locations where WAN repair may take time. Remote sites, outdoor cabinets, underground routes, and leased communication lines may not be restored immediately. A local survivability layer buys time for repair teams while allowing the site to maintain essential internal coordination.
Improving resilience without overcomplicating the whole network
Resilience is often associated with full redundancy: duplicate servers, duplicate links, backup data centers, multiple carriers, and parallel systems. These designs can be necessary for large or mission-critical networks, but they may also be expensive and complex. Local Survivability provides a focused resilience method by protecting the most important site-level communication functions without duplicating the entire central platform at every location.
This makes it attractive for distributed organizations. A branch office may not need a full communications server with every advanced feature. A station or plant may not need complete platform duplication. What it needs is the ability to keep basic calling, emergency routing, and local service access working during disconnection. Survivability targets that practical requirement.
The architecture can be scaled according to risk. A low-risk branch may only require local emergency calls and internal extension fallback. A critical industrial facility may need local registration, local trunks, emergency phones, paging access, and operator console fallback. A transport network may require station-level continuity and controlled reconnection to the central command center when the link returns.
By matching survivability depth to site importance, organizations can improve resilience without building unnecessarily heavy infrastructure everywhere. The goal is not to make every site fully independent; it is to ensure that each site retains the communication functions it truly needs during abnormal network conditions.
Shortening recovery time after service interruption
Local Survivability can reduce the operational impact of outages because services do not collapse completely during the failure. When the central path is restored, the system can return from local fallback to centralized operation. This transition may be automatic or controlled, depending on the platform design and project requirements.
Without survivability, a WAN outage may trigger many secondary problems. Users repeatedly attempt failed calls, operators receive complaints, emergency routing becomes uncertain, and maintenance teams must explain why local devices cannot communicate even though they are physically close to each other. Recovery is not only about restoring the network link; it is also about restoring user confidence and service order.
With survivability, the site continues operating in a limited but organized mode. Local users may notice that some central services are unavailable, but essential communication remains possible. When the main platform returns, registrations, routing, and policy control can be synchronized back to normal. This makes the outage easier to manage and less disruptive to daily operations.
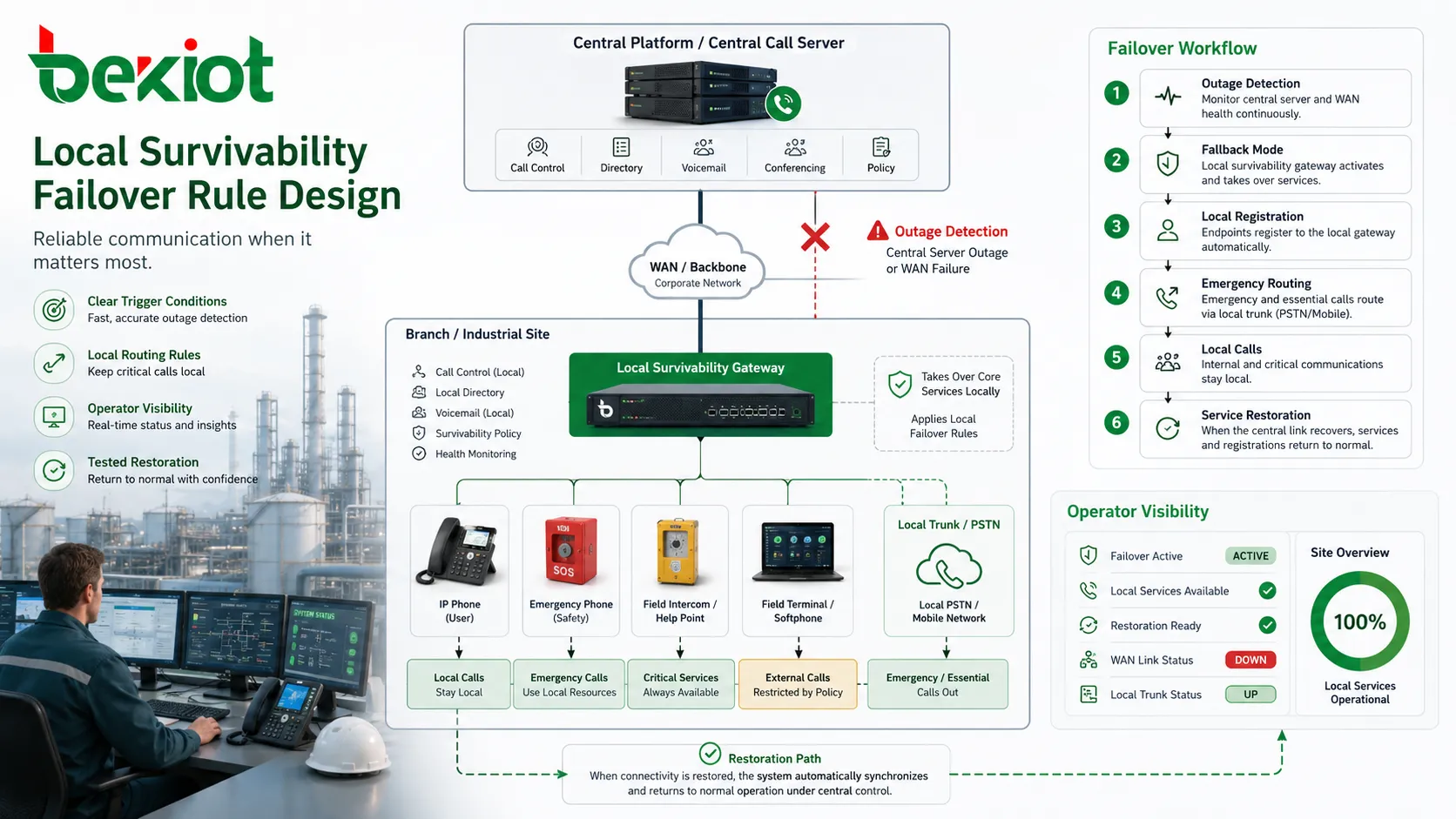
Recovery planning should include what happens after the failure ends. The system should avoid duplicate registrations, call routing confusion, inconsistent user states, or delayed restoration. Maintenance teams should be able to see when a site entered survivable mode, which calls were handled locally, and when normal mode resumed. These records help verify that the failover process behaved correctly.
Preserving user experience under degraded conditions
Users do not usually think in terms of call servers, WAN routing, SIP registration, or trunk fallback. They expect the phone, emergency terminal, intercom, or console to work when needed. Local Survivability helps preserve this experience by keeping the most familiar communication actions available even when the wider network is impaired.
For example, a user may still dial a local extension, contact the security desk, reach the control room, or activate an emergency call point. The system may be operating in fallback mode, but the user experience remains close enough to normal for critical tasks. This reduces confusion and prevents people from abandoning official communication procedures in favor of informal workarounds.
Preserving user experience also reduces training burden. If fallback behavior is designed to follow familiar dialing patterns and response routes, users do not need to memorize a separate emergency communication method for network outages. The system should adapt to the failure, not force every user to change behavior during a stressful moment.
However, not every feature can or should remain available locally. Advanced services such as centralized directories, remote recording, cross-site conferencing, cloud voicemail, or global routing may be unavailable during isolation. A good deployment clearly defines which functions are guaranteed locally and which depend on the central system. This avoids unrealistic expectations and improves operational planning.
Designing failover rules that operators can trust
Survivability depends on rules. The system must know when to enter fallback mode, which services should be taken over locally, which numbers should be routed through local resources, and when normal operation should resume. If these rules are unclear, survivability can create confusion instead of stability.
Trigger conditions are the first design question. A site may enter survivable mode when it loses contact with the central call server, when SIP registration fails, when WAN latency exceeds a threshold, or when a primary trunk becomes unavailable. The trigger should be specific enough to avoid unnecessary failover but sensitive enough to respond before users experience widespread failure.
Routing rules are equally important. Local calls should remain local where appropriate. Emergency calls may be sent to local operators or backup trunks. External calls may be restricted to essential numbers if local trunk capacity is limited. Calls to other sites may be blocked, rerouted, or handled through alternative paths. Operators should understand these rules before an outage occurs.
Trust comes from testing and documentation. If staff do not know what survivable mode means, they may assume the system is broken even when it is working correctly. Clear status indicators, maintenance logs, operator guidance, and regular failover tests help build confidence. A survivability design that no one understands will not deliver its full operational value.
Deployment planning for branch and multi-site architectures
Local Survivability should be planned according to site role. A small branch, large factory, public transport station, campus building, remote utility facility, and emergency command point do not need the same survivability design. The first step is to identify which communication functions must remain available if the central platform is unreachable.
Key questions include: Should local extensions still call each other? Should emergency calls go to a local desk or external trunk? Is public network access required? Are paging or announcements needed locally? Should radio or intercom links remain active? How many simultaneous calls must be supported? How long could the site remain isolated? These questions help define the size and function of the local survivability node.
Network design should also be reviewed. Local devices must be able to reach the fallback node even when the WAN is down. This means local switching, VLAN design, IP addressing, DHCP behavior, DNS dependency, power backup, and gateway placement all matter. A survivability feature cannot work if local endpoints lose network access or power at the same time.
For multi-site deployments, configuration consistency is important. Each site may have its own local fallback rules, but the overall design should follow a standard pattern where possible. Standard templates reduce engineering errors and make maintenance easier. Site-specific exceptions can still be added for high-risk or special-purpose locations.
Operational monitoring and maintenance value
Local Survivability should not be treated as a feature that is configured once and forgotten. Its value depends on whether the local fallback path remains healthy. Maintenance teams should monitor the status of local gateways, backup trunks, endpoint registration behavior, power conditions, and software versions. A survivability node that is offline or misconfigured may not be noticed until a real outage occurs.
Regular testing is essential. Engineers should simulate central server unavailability or WAN disconnection in a controlled way and verify whether local calls, emergency calls, and fallback routes behave as expected. These tests should be documented, especially in environments where safety or operational continuity is important.
Monitoring should also include event records. When a site enters survivable mode, the system should generate logs or alarms so that maintenance teams understand what happened. If failover occurs frequently, the issue may be WAN instability, central server reachability, incorrect thresholds, or local network problems. Survivability protects service, but frequent activation still indicates an underlying issue that should be corrected.
After a real outage, records can help evaluate performance. Did local calling remain available? Were emergency calls routed correctly? Did users report confusion? Did the system return to normal mode cleanly? These questions help refine the design and improve future resilience.
Common limitations that should be understood before deployment
Local Survivability is valuable, but it is not the same as full system duplication. Some centralized services may not be available during isolation. Depending on the architecture, this may include cross-site calling, centralized recording, cloud directory lookup, advanced conferencing, centralized voicemail, global call queues, or remote administrator control. These limitations should be explained before deployment.
Capacity may also be limited. A local survivability node may support only a defined number of users, calls, trunks, or features. If the site expects all users to behave normally during a WAN outage, the fallback system must be sized accordingly. If only emergency and essential communication are required, a smaller design may be enough.
Another limitation is data consistency. During fallback, some call records, device states, or configuration changes may be stored locally and synchronized later, or they may not be fully available to the central platform. The project should define how records are handled and what information is required for audit or reporting.
Understanding these limits does not weaken the case for survivability. It makes the deployment more realistic. The strongest designs are those that clearly define what survives locally, what depends on the central system, and how users and operators should behave during degraded operation.
Long-term business value of site-level resilience
The long-term value of Local Survivability comes from reducing operational risk across distributed environments. A single outage may be rare, but when it occurs, the cost can be high. Communication loss can delay maintenance, disrupt production, affect customer service, weaken emergency response, or create safety risks. Survivability reduces the chance that a network fault becomes a full operational failure.
For organizations with many sites, the value increases further. Even if each site experiences only occasional connectivity issues, the total risk across the network can be significant. Local fallback capability creates a more resilient operating model, especially where sites are geographically dispersed or dependent on leased WAN links.
Survivability also supports modernization. Organizations can move toward centralized or cloud-based communication platforms while still keeping local protection for critical sites. This makes migration less risky because the new architecture does not remove all local independence. It combines centralized efficiency with site-level continuity.
In practical deployment terms, Local Survivability is not only a technical feature. It is a business continuity measure, a safety support layer, and a way to make distributed communication architecture more tolerant of real-world network problems.
FAQ
Is Local Survivability only needed for large organizations?
No. It is useful for any site where communication must continue during WAN or central server failure. Small branches, remote facilities, industrial stations, campuses, and transport sites may all need local fallback if the business impact of communication loss is high.
Does Local Survivability replace central redundancy?
No. Central redundancy protects the main platform, while Local Survivability protects communication at the site level when the site cannot reach the central platform. They solve different parts of the resilience problem and can be used together.
What services usually remain available during survivable mode?
Common services include local extension calling, emergency routing, access to local trunks, limited registration fallback, and predefined essential communication paths. Advanced centralized services may not remain available unless specifically designed for local operation.
How often should survivability failover be tested?
Testing frequency depends on risk level, but critical sites should test failover regularly and after major network or configuration changes. Testing should verify local calls, emergency routes, trunk access, restoration behavior, and operator visibility.
What is the most common deployment mistake?
The most common mistake is enabling a survivability feature without designing the full fallback workflow. The project must define trigger conditions, local routing, emergency behavior, capacity, user expectations, monitoring, and recovery procedures before relying on it.







