An SLA becomes useful when service expectations need to move from verbal promise to measurable operation.
A customer may expect stable uptime, fast fault recovery, clear support response, predictable maintenance windows, and transparent reporting. A provider may need clear boundaries for responsibility, measurable targets, escalation rules, and evidence-based service evaluation. The Service Level Agreement connects these two sides by defining what will be delivered, how it will be measured, and what happens when the agreed level is not achieved.
The operating logic behind measurable service commitments
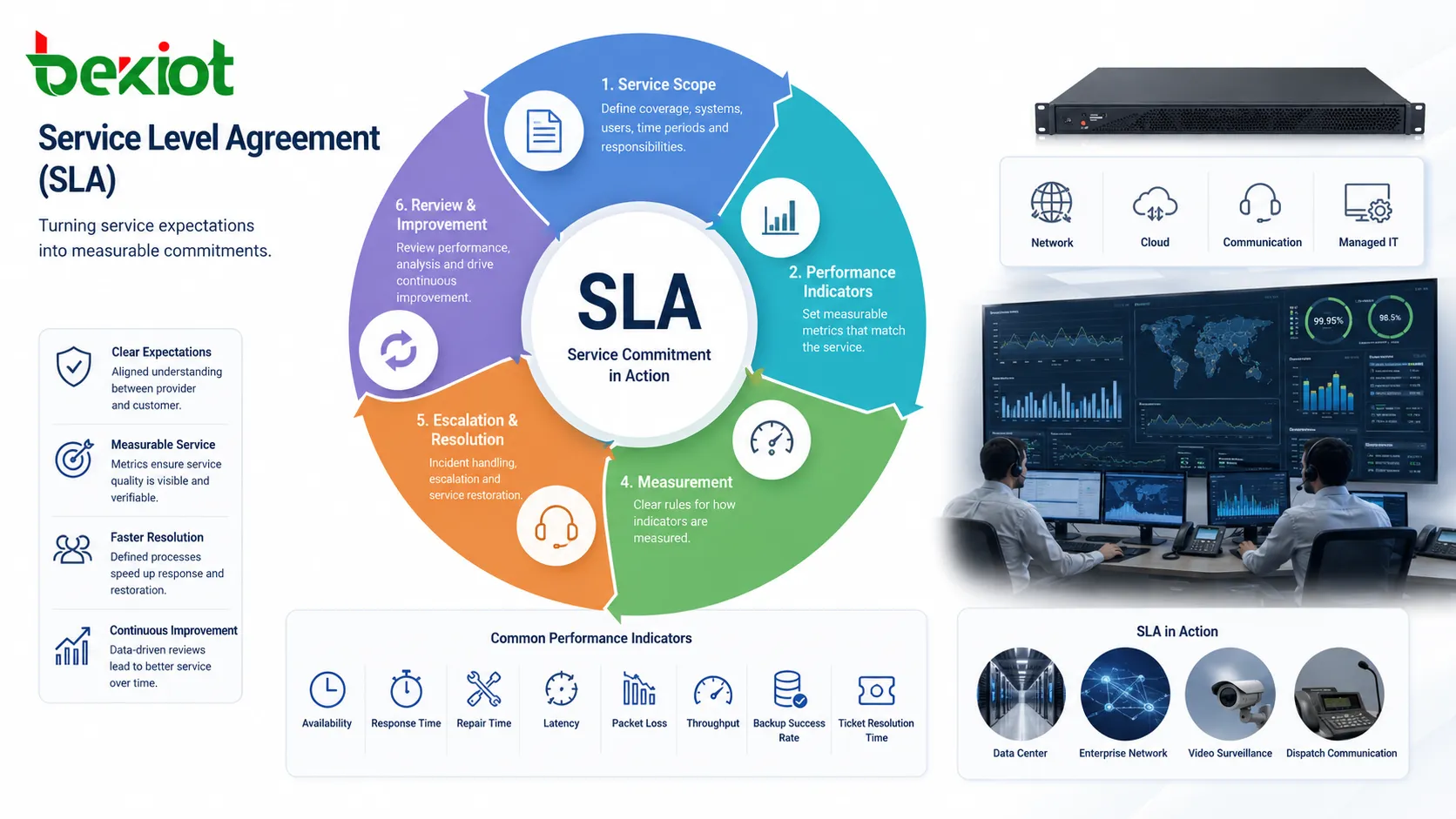
A Service Level Agreement, commonly called an SLA, is a formal agreement that defines the expected level of service between a provider and a customer. It can apply to network services, cloud platforms, data centers, communication systems, managed IT services, software platforms, maintenance contracts, security operations, and many other service-based relationships. Its main purpose is to turn service expectations into measurable commitments.
The working principle of an SLA begins with defining the service scope. This includes what service is covered, which systems or sites are included, which users are supported, what time periods apply, and which responsibilities belong to the provider or the customer. Without this scope, later performance judgment becomes unclear. A provider may believe only the core platform is covered, while the customer may expect end-to-end user experience to be included.
Once the scope is clear, the agreement defines performance indicators. These may include availability, response time, repair time, service restoration time, incident handling time, data backup success rate, ticket resolution time, latency, packet loss, throughput, or support coverage. The selected indicators should match the nature of the service. A network SLA may focus on availability and delay, while a maintenance SLA may focus on response and repair time.
The SLA then defines how those indicators are measured. This is important because two sides may interpret the same term differently. For example, uptime may be calculated monthly or annually, measured at the provider edge or customer endpoint, and may or may not exclude scheduled maintenance. Good SLA operation depends on transparent measurement rules, not only headline percentages.
In practice, an SLA operates as a continuous service management framework. It sets expectations before service begins, guides monitoring during operation, supports escalation when faults occur, and provides evidence for review after incidents. It is both a contractual tool and an operational management method.
From agreement text to daily service execution
An SLA is often written as a document, but its real value appears only when it is translated into daily operations. The agreement should influence how services are monitored, how tickets are handled, how teams respond to incidents, how customers receive updates, and how performance is reviewed. If the SLA remains only a signed document, it cannot improve service quality.
Daily execution usually begins with service monitoring. The provider needs tools or processes to observe whether the service is meeting agreed targets. For a network service, this may include link availability, latency, jitter, packet loss, interface status, and device health. For a cloud or software service, it may include application availability, transaction success, API response time, resource usage, and error rate.
Incident management is another important part of SLA operation. When a fault occurs, the SLA should define how quickly the provider must acknowledge the issue, how it should be categorized, how escalation works, and what restoration target applies. A high-severity incident may require immediate response and frequent updates, while a low-priority request may follow a longer handling window.
The SLA also influences internal staffing and support structure. If the agreement promises 24/7 response, the provider must have the people, tools, and procedures to support that promise. If the SLA defines strict repair time for critical equipment, spare parts, remote access, and field service readiness must be planned in advance. The document sets the promise, but operations must make the promise achievable.
Customer communication is part of execution as well. During incidents, customers need to know whether the issue has been received, what impact is expected, what actions are being taken, and when the next update will arrive. A good SLA does not only define technical numbers; it also helps avoid uncertainty during service disruption.
Performance indicators that give the agreement real meaning
The quality of an SLA depends heavily on the indicators it uses. Vague statements such as “high reliability,” “fast support,” or “stable operation” are not enough. They sound positive but cannot be judged consistently. Measurable indicators allow both sides to understand whether the service is performing as promised.
Availability is one of the most common indicators. It expresses how much time a service is usable within a defined period. For example, monthly availability may be measured as the percentage of time the service remains available during the month. The exact calculation must be clear, including whether planned maintenance, customer-side faults, force majeure events, or third-party issues are excluded.
Response time is another widely used indicator. It usually refers to how quickly the provider acknowledges or begins handling an incident after receiving a report. This should not be confused with repair time. A provider may respond within 15 minutes but require several hours to restore the service. Both values can be important, but they measure different stages of support.
Resolution time or restoration time measures how long it takes to return the service to normal or acceptable operation. This indicator is especially important for business-critical systems. In some contracts, different severity levels have different restoration targets. A complete outage may require rapid restoration, while a minor configuration request may have a longer service window.
Other indicators may include latency, jitter, packet loss, throughput, transaction success rate, backup completion rate, data recovery point, service desk availability, security incident handling time, or preventive maintenance completion rate. The correct indicators should reflect what the customer actually depends on, not merely what is easiest for the provider to measure.
How severity levels shape response behavior
Many SLAs use severity levels to classify incidents. This helps avoid treating every issue in the same way. A full service outage, partial degradation, minor fault, information request, and planned change should not consume the same response resources. Severity classification allows the provider to match response effort with business impact.
A high-severity incident may involve complete service interruption, major safety impact, significant business loss, or loss of critical system function. It usually requires immediate acknowledgement, rapid escalation, senior technical involvement, frequent updates, and a strict restoration target. In contrast, a low-severity issue may involve a question, minor inconvenience, cosmetic defect, or request that does not affect core operation.
The key is defining severity based on impact, not emotion. A customer may feel that every problem is urgent, while a provider may prefer to classify problems conservatively. The SLA should describe severity levels clearly so that both sides can agree on the category when an incident occurs. This reduces arguments during stressful situations.
Severity classification also affects escalation. If a fault is not resolved within a defined time, it may move to a higher support level, involve management, or trigger additional reporting. Escalation rules help ensure that serious incidents do not remain stuck at the first line of support. They also give the customer confidence that unresolved problems will receive stronger attention over time.
In mature service operations, severity data is reviewed periodically. If many incidents are classified as high severity, the service may have design or stability problems. If incidents are often reclassified after dispute, the severity definitions may be unclear. SLA operation should therefore include regular review of classification accuracy.
Monitoring and reporting as the evidence layer
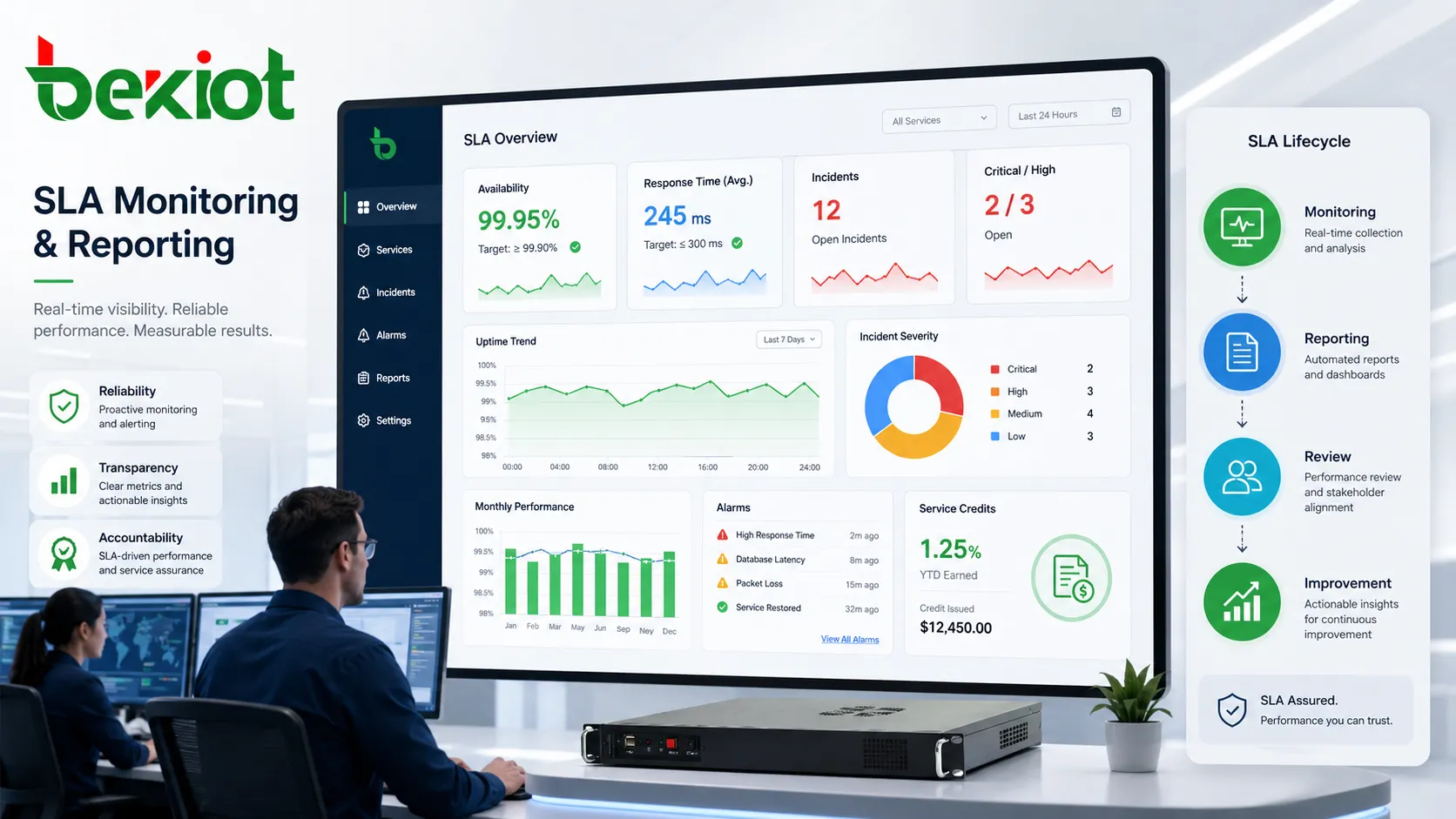
An SLA is difficult to enforce or improve without evidence. Monitoring and reporting provide that evidence. They show whether targets were met, where service quality changed, which incidents occurred, how quickly teams responded, and whether recurring problems are developing. Without reports, the SLA becomes a promise that is hard to verify.
Monitoring can be automated or manual depending on the service. Automated tools may track availability, traffic, device status, server health, transaction success, alarm events, response times, and error rates. Manual records may include maintenance visits, customer feedback, support notes, inspection results, and post-incident reports. The most reliable SLA reporting combines system-generated data with verified operational records.
Reporting frequency should match the service type. Critical services may require real-time dashboards, daily summaries, or immediate incident notifications. Standard managed services may use monthly reports. Long-term maintenance contracts may include quarterly service reviews. The report should not simply list numbers; it should explain trends, exceptions, root causes, and improvement actions.
Data accuracy is essential. If the monitoring point is poorly chosen, the report may not reflect real customer experience. For example, measuring service availability only inside the provider’s data center may not reveal access problems at the customer site. Measuring application uptime without checking transaction success may hide functional failures. The SLA should define where and how measurements are collected.
Good reporting creates transparency. It reduces disputes because both parties can discuss the same evidence. It also supports improvement. If reports show repeated outages in one location, slow response during certain hours, or frequent failures in one system module, the provider and customer can focus corrective actions on real patterns instead of isolated complaints.
Escalation, remedies, and service credits
An SLA should define what happens when service targets are missed. This is where escalation, remedies, and service credits become relevant. These mechanisms do not prevent faults by themselves, but they create accountability and motivate both sides to handle service problems seriously.
Escalation defines how unresolved issues move through the support structure. A first-line engineer may handle basic troubleshooting. If the issue continues, it may move to a specialist team, vendor support, network operations center, or management level. Escalation rules should include time thresholds, contact paths, responsibility ownership, and update requirements. This prevents serious incidents from remaining unresolved due to unclear ownership.
Remedies define the consequences of missed service levels. In some agreements, the provider may offer service credits if availability falls below the agreed target. In others, the remedy may include corrective action plans, free maintenance extensions, management review, or contractual termination rights after repeated failures. The appropriate remedy depends on the service type and business relationship.
Service credits should be designed carefully. They may compensate the customer financially, but they rarely cover the full business impact of service failure. For critical systems, restoration and prevention are usually more important than small credits. The SLA should therefore treat credits as accountability tools, not as substitutes for reliability engineering.
It is also important to define exclusions. Service credits may not apply when the failure is caused by customer-side configuration, unauthorized changes, power failure outside the provider’s control, scheduled maintenance, force majeure, or third-party service dependencies. Clear exclusions reduce disputes and make the agreement more realistic.
Advantages for customers and service providers
For customers, the main advantage of an SLA is predictability. They know what level of service to expect, how quickly incidents should be handled, which services are covered, and what evidence will be used to judge performance. This helps with business planning, risk management, and internal accountability. Instead of relying on informal promises, customers can align their operations with defined service commitments.
The SLA also helps customers compare providers. Two services may look similar in price and function, but their service commitments may differ significantly. One provider may offer stronger uptime guarantees, faster response, clearer escalation, better reporting, or more suitable maintenance windows. An SLA reveals these differences in operational terms.
For providers, an SLA helps define boundaries. It clarifies what is included, what is excluded, how incidents are classified, and what responsibilities the customer must fulfill. This reduces unrealistic expectations and supports more efficient service delivery. A provider can plan staffing, monitoring, spare parts, and support processes based on agreed commitments.
The SLA also improves internal management. Support teams can prioritize work according to severity and contractual obligations. Operations managers can identify recurring problems. Sales and account teams can explain service value more clearly. Finance teams can assess risk linked to service credits or penalties. In this way, the SLA becomes a management tool inside the provider organization as well.
For both sides, the greatest advantage is alignment. The customer’s expectations and the provider’s delivery process are connected through agreed metrics and procedures. This reduces ambiguity and creates a shared reference point when service quality is discussed.
Operational value beyond contract protection
Some organizations treat the SLA mainly as a legal document, but its operational value is often greater than its legal value. A well-designed SLA helps teams manage services more systematically. It encourages monitoring, documentation, escalation, root cause analysis, capacity planning, and continuous improvement.
For example, if the SLA defines strict response targets, the provider must ensure that support channels are monitored properly. If it defines availability targets, the provider must maintain redundancy, backup plans, and incident detection. If it defines reporting obligations, the provider must collect and organize service data. These operational practices improve service maturity.
Customers also benefit operationally. Internal teams can use SLA reports to understand service dependencies, justify upgrades, plan maintenance windows, and evaluate risk. If a business unit depends heavily on a service with weak commitments, management can identify the gap before a major incident occurs. The SLA makes service dependency more visible.
In complex environments, SLAs can also support multi-provider coordination. A customer may rely on one provider for cloud services, another for network connectivity, another for security monitoring, and another for on-site maintenance. Clear service commitments help identify where responsibilities meet and where gaps may exist.
When used well, an SLA becomes part of service governance. It helps move service management from reactive complaint handling to structured performance control. This is where the agreement creates long-term value beyond contract language.
Common mistakes in SLA design
One common mistake is using impressive numbers without practical measurement rules. A promise of high availability may sound strong, but it becomes weak if the calculation excludes too many conditions or uses a measurement point that does not reflect customer experience. The SLA should define not only the target, but also the calculation method.
Another mistake is choosing too many metrics. A long list of indicators may look thorough, but it can make service management complicated and unfocused. The best SLA metrics are those directly linked to business impact. If a metric does not influence service quality, operational decisions, or customer risk, it may not belong in the core agreement.
Poor severity definitions are also common. If severity levels are vague, disputes may occur whenever an incident happens. The agreement should describe impact levels clearly and include examples where possible. This makes incident classification faster and more consistent.
Some SLAs fail because responsibilities are one-sided. Service quality often depends on both provider and customer behavior. The provider may need access, accurate fault reports, approved maintenance windows, contact information, power conditions, or customer-side configuration support. If customer responsibilities are not defined, restoration may be delayed even when the provider is ready to act.
A final mistake is failing to review the SLA after service changes. Business needs, user numbers, system architecture, security requirements, and service dependencies can change over time. An SLA that was suitable at the start of a contract may become outdated. Regular review keeps the agreement aligned with real operating conditions.
How to judge whether an SLA is effective
An effective SLA should be clear, measurable, relevant, realistic, and enforceable. Clarity means that both parties understand the service scope, targets, measurement rules, severity levels, reporting process, and remedies. If the agreement requires constant interpretation, it is not operationally strong.
Measurability means that performance can be verified with reliable data. The agreement should identify where data comes from, how calculations are performed, and how disputes are resolved. A target that cannot be measured consistently will not support fair judgment.
Relevance means that the SLA measures what actually matters to the customer’s operation. A low-level technical metric may be useful, but only if it connects to service experience or business impact. The agreement should avoid measuring easy but unimportant indicators while ignoring critical user-facing performance.
Realism means that the targets match the architecture, budget, staffing, risk level, and service environment. Overly aggressive targets may look attractive but become unsustainable. Weak targets may protect the provider but fail to support the customer’s needs. A good SLA balances ambition with operational feasibility.
Enforceability means that missed targets lead to defined actions. This does not always mean penalties. It may include escalation, corrective action, service credits, management review, or improvement plans. The key is that the SLA should create follow-up behavior, not only record failure after the fact.

FAQ
Is an SLA only needed for outsourced services?
No. SLAs are useful for outsourced services, but they can also be used inside an organization between IT teams, facility teams, business departments, or shared service centers. Internal SLAs help define service expectations and accountability even when no external vendor is involved.
What is the difference between SLA and KPI?
An SLA is an agreement that defines service commitments between parties. A KPI is a performance indicator used to measure progress or results. SLA targets often use KPIs, but not every KPI is part of a contractual service commitment.
Can an SLA guarantee that failures will never happen?
No. An SLA does not eliminate failures. It defines expected performance, response behavior, measurement rules, and remedies. Good service design reduces failure risk, while the SLA defines how performance will be judged and managed.
Who should review SLA reports?
Both operational teams and management should review them. Technical teams need the details for troubleshooting and improvement, while managers need trend information, risk visibility, and evidence of whether the service supports business requirements.
How often should an SLA be updated?
It should be reviewed whenever service scope, architecture, user scale, business dependency, compliance requirements, or provider responsibilities change. Even without major changes, a periodic review helps keep the agreement aligned with real operating needs.