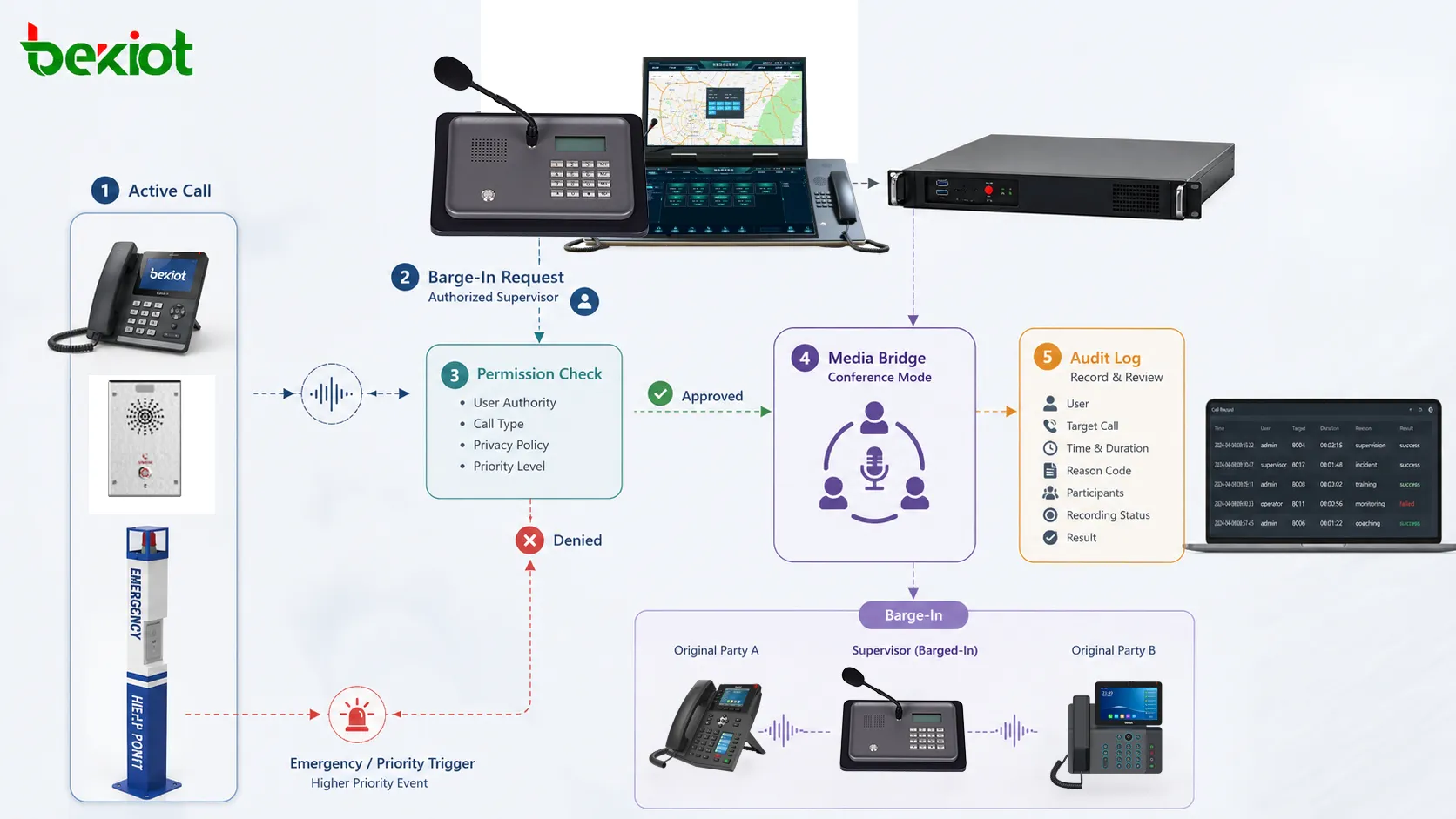
A single port can become a single interruption point. In many communication, control, security, industrial, and information systems, service continuity depends not only on software stability but also on the physical and logical path used to transmit data. If one network interface, cable, switch port, optical link, or communication channel fails, the entire service may become unreachable even when the main device is still operating normally.
Why one connection is often not enough
Many systems are designed around continuous access. A server must remain reachable, a controller must continue exchanging data, a monitoring terminal must keep reporting status, and a communication device must stay connected to the management platform. In these environments, the port is more than a connection point. It is part of the service path.
When only one port is used, several common faults can interrupt operation. The cable may be damaged, a switch port may fail, a network module may become unstable, a connector may loosen, a configuration change may block traffic, or a maintenance action may temporarily disconnect the link. These problems may look small, but they can cause full service interruption if there is no secondary path.
Dual-port redundancy addresses this weakness by providing two available connection points for one service or one device. The second port does not exist only for decoration. It is used to support failover, link protection, load sharing, network separation, maintenance flexibility, or path diversity, depending on the system design.
The core idea is simple: the service should not depend on one physical or logical connection. If the primary path becomes unavailable, the system should have another prepared path to continue operation. This reduces the chance that a local port-level fault becomes a system-level failure.
The basic operating logic
Dual-port redundancy usually works by connecting one device to two ports, two cables, two switch interfaces, two network paths, or two communication channels. The system then uses a redundancy mechanism to decide how the two ports behave during normal operation and fault conditions.
In an active-standby design, one port carries traffic during normal operation, while the second port waits as a backup. If the active port fails, the standby port takes over. This design is common where the main goal is simple continuity and predictable traffic behavior. It is easier to manage than more complex multi-path designs.
In an active-active design, both ports may be used at the same time. Depending on the protocol and configuration, traffic may be distributed across both links, separated by service type, or balanced according to flow rules. This can improve bandwidth use, but it requires more careful configuration to avoid loops, packet disorder, asymmetric routing, or difficult troubleshooting.
Some systems use the two ports for network isolation rather than direct failover. For example, one port may connect to a production network and the other to a management network. In this case, the design improves operational safety and access control, but it may not automatically provide failover unless the system supports it.
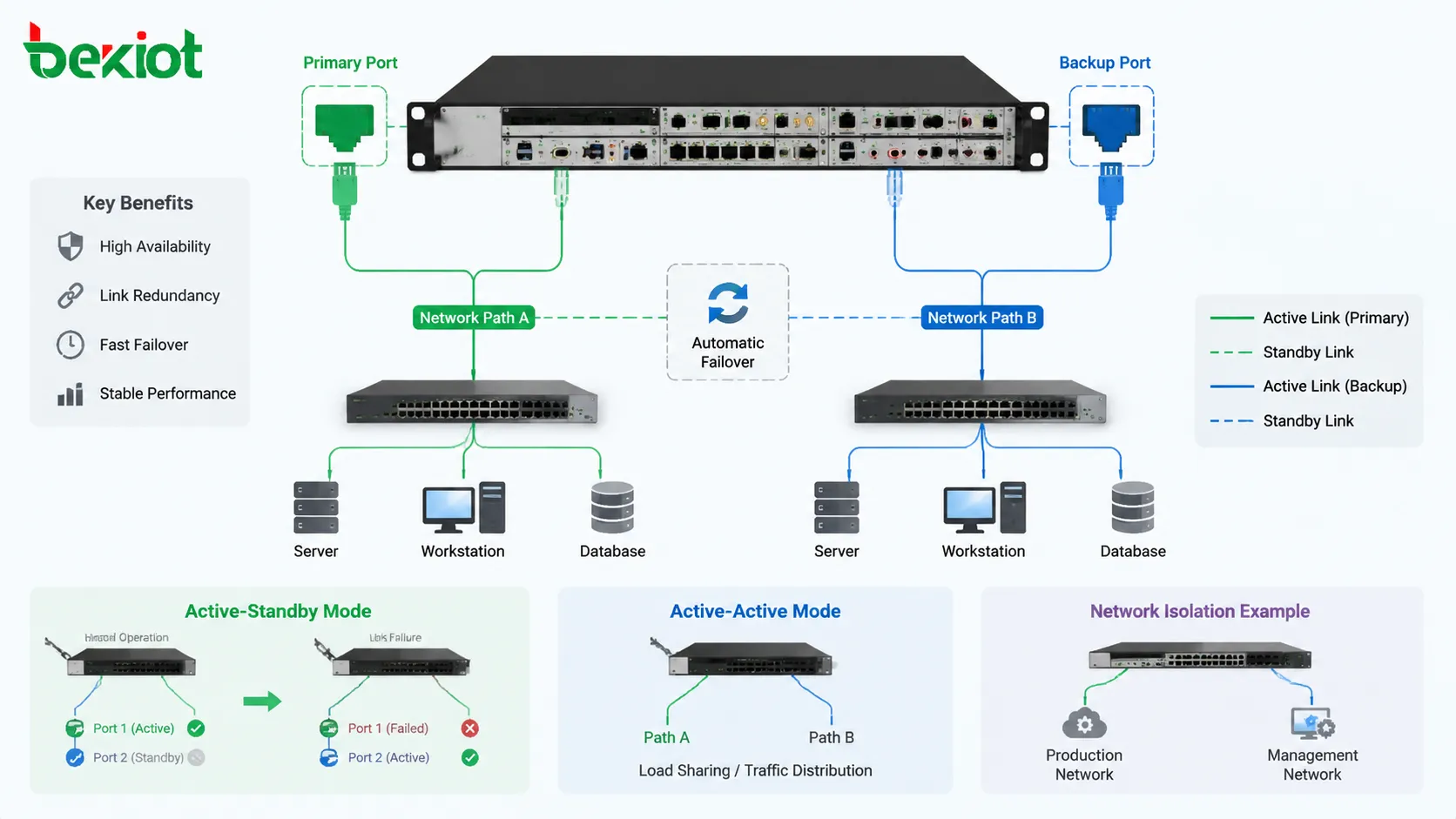
Key characteristics in system design
The first characteristic is path backup. A second port gives the system another route for communication when the first route is unavailable. This does not automatically guarantee full continuity, because the backup path must also be connected, configured, tested, and monitored. However, it provides the basic physical condition for redundancy.
The second characteristic is link state awareness. A practical redundancy design should know whether a port is up, down, unstable, or unable to pass traffic. Simple physical link detection is useful, but it may not be enough in all cases. A port may show link-up while upstream routing, VLAN access, gateway reachability, or application connectivity has already failed.
The third characteristic is controlled switching. Failover should not be random. The system should define which port is preferred, when switching happens, how long detection takes, whether automatic recovery is allowed, and whether traffic should return to the original port after it becomes available. Poor switching behavior can create repeated flapping and service instability.
The fourth characteristic is configuration consistency. If two ports are intended to provide the same service path, both sides must support the required VLAN, IP addressing, routing, firewall rules, access permissions, and service policies. A backup port that uses incomplete configuration may appear ready but fail during an actual incident.
The fifth characteristic is status visibility. Operators and maintenance staff should be able to see which port is active, whether the standby path is healthy, when a switchover occurred, and whether errors are increasing. Redundancy without monitoring can create false confidence.
Common working modes
Different systems use dual ports in different ways. The correct mode depends on system function, network architecture, risk tolerance, and maintenance requirements. Treating all dual-port devices as if they work the same way is a common design mistake.
| Working mode | How it behaves | Typical advantage | Main caution |
|---|---|---|---|
| Active-standby | One port carries traffic while the second port waits for failure | Simple failover and predictable traffic path | Standby path must be tested regularly |
| Active-active | Both ports may carry traffic at the same time | Higher link utilization and possible bandwidth improvement | Requires careful design to avoid routing or loop issues |
| Link aggregation | Multiple physical links are treated as one logical connection | Combines redundancy with capacity expansion | Both ends must support matching aggregation settings |
| Network separation | Each port connects to a different network segment | Improves management isolation and traffic separation | May not provide automatic failover unless designed for it |
| Dual uplink path | Ports connect to different switches or upstream paths | Reduces dependence on one switch or one cable route | Switching, routing, and loop control must be planned |
Active-standby mode is often preferred for critical but conservative systems. It avoids unnecessary traffic complexity and makes fault behavior easier to understand. The standby port becomes valuable because it is quiet during normal operation but available when the main path fails.
Active-active mode is suitable when the system can safely use both ports at the same time. It may improve throughput or distribute different services across separate paths. However, it requires more attention to routing, traffic symmetry, switch behavior, and troubleshooting methods.
Network separation should not be confused with redundancy. A device may have two ports, one for service traffic and one for management access, but the management port may not take over production traffic. Before calling a design redundant, the actual failure behavior must be confirmed.
How failover should happen
Failover is the most important behavior in many dual-port designs. It is the process by which traffic moves from the failed or unavailable port to the backup port. A good failover process should be fast enough to meet service needs, stable enough to avoid unnecessary switching, and visible enough for maintenance teams to understand what happened.
The failover trigger may be physical link loss, heartbeat failure, gateway unreachable status, service communication failure, or manual operator action. Physical link loss is easy to detect, but it may not capture all failures. For example, the cable between the device and the first switch may still be connected while the upstream network behind that switch has failed.
Detection time must match the application. Some systems can tolerate several seconds of interruption. Others require much faster switching. Voice communication, monitoring alarms, industrial data exchange, and real-time control may be more sensitive than ordinary file transfer or background reporting. The acceptable failover time should be defined before deployment.
After failover, the system should continue communication through the backup path. Depending on the design, existing sessions may survive, reconnect, or restart. Some applications handle short interruptions gracefully. Others may need session recovery, retry logic, or application-level reconnection. Port redundancy improves path availability, but it does not automatically solve every application continuity problem.
Recovery behavior also matters. When the original port becomes available again, the system may remain on the backup path or switch back to the preferred path. Automatic return can restore the intended architecture, but it may also create another interruption. In some critical environments, manual recovery is preferred so that operators can choose a safe time to return traffic.
Reliability benefits in daily operation
The most direct advantage is reduced downtime caused by local connection faults. Cable damage, connector looseness, port failure, switch interface problems, or accidental unplugging may no longer stop the service immediately. If the backup path is healthy, the system can continue operating while maintenance staff inspect the failed side.
Another advantage is stronger tolerance against maintenance activity. Network teams may need to replace a switch, move a cable, adjust a port, upgrade firmware, or test a circuit. With only one connection, such work often requires service interruption. With dual-port redundancy, maintenance can sometimes be performed on one path while the other path keeps the system reachable.
Dual ports can also improve operational confidence. Operators know that one link problem does not necessarily mean total failure. This is important for systems that must run continuously, such as monitoring platforms, communication servers, industrial gateways, security devices, data collection systems, and control-room equipment.
Reliability improvement is not only a technical benefit. It also reduces pressure on maintenance teams. When a single link failure does not immediately stop the service, staff have more time to diagnose the root cause, replace hardware, check logs, or coordinate scheduled repair instead of reacting under emergency conditions.
Continuity value for critical services
For critical services, continuity is more valuable than raw bandwidth. A system may not need high data speed, but it may need stable availability. Dual-port redundancy is often used because the cost of interruption is higher than the cost of adding another link.
In communication systems, a port failure may affect registration, call control, signaling, media transmission, dispatch access, or platform management. In monitoring systems, it may interrupt alarm reporting or camera access. In industrial systems, it may delay data collection or control commands. In business platforms, it may block users or connected applications.
Continuity depends on the complete path, not only the device port. A well-designed dual-port environment should avoid sharing the same weak point. If both ports connect to the same switch, same power supply, same cable route, or same upstream failure domain, redundancy may be limited. The two paths should be separated where risk justifies it.
The advantage becomes clearer during faults that are small but disruptive. A switch port may fail while the switch itself continues running. A cable may be damaged during site work. A fiber module may become unstable. A network patch may affect one VLAN path. Dual-port redundancy gives the system another way to remain connected during these localized problems.

Performance and traffic management advantages
Although redundancy is mainly about availability, dual ports can also support better traffic management. In some designs, different traffic types can be separated between ports. For example, service traffic may use one port while management traffic uses another. This reduces competition between operational data and administrative access.
Traffic separation can improve predictability. Monitoring, configuration, backup, log collection, and maintenance access may create bursts of traffic. If this traffic shares the same path with real-time service data, it may affect latency or packet delivery. Separate ports allow the system designer to apply different policies to different traffic groups.
In active-active or link aggregation scenarios, dual ports may also increase available capacity. This is useful when a single physical interface cannot provide enough throughput or when multiple users, devices, or data streams must be supported. However, bandwidth improvement depends on the actual aggregation method and traffic distribution rules.
It is important not to overstate this advantage. Some dual-port designs provide redundancy only, not higher throughput. Some link aggregation methods distribute traffic by session or flow rather than doubling the speed of one single connection. Performance expectations should be based on actual system behavior, not only the number of ports.
Application value in industrial environments
Industrial sites often contain long cable routes, electrical interference, temperature variation, vibration, dust, humidity, and frequent maintenance activity. Network paths may pass through cabinets, workshops, outdoor routes, machinery areas, or unmanned stations. In such environments, physical connection reliability is a real operating concern.
Dual-port redundancy is useful for industrial switches, controllers, gateways, servers, data acquisition equipment, monitoring terminals, and communication devices. If one port or one network path fails, the secondary path can help maintain communication with the central platform or local control system.
Industrial applications also require clear fault localization. When a communication interruption occurs, teams need to know whether the fault is at the device port, cable, switch, upstream network, power supply, or application layer. A dual-port design with proper status reporting can help isolate the failed segment more quickly.
For remote industrial sites, redundancy is even more valuable. Sending technicians to a field station may take hours. If the secondary port keeps the system online, operators can continue remote diagnosis and avoid immediate site dispatch. This reduces downtime and improves maintenance planning.
Application value in communication and dispatch systems
Communication and dispatch systems often require continuous availability because users expect calls, alerts, paging, intercom, or command communication to work whenever needed. A single network connection can become a weak point if the device depends on IP transport or centralized management.
Dual-port redundancy can protect access between communication servers, dispatch consoles, IP terminals, gateways, and management systems. If one link becomes unavailable, the backup link can maintain signaling, device registration, management visibility, or media-related traffic depending on system architecture.
In dispatch environments, service interruption may affect coordination between operators and field staff. Even a short outage can create confusion during emergency response, production coordination, transportation management, or facility security. Redundant ports reduce the chance that a simple network fault interrupts operational communication.
For voice and real-time communication, failover design should consider session behavior. Some calls or sessions may need to reconnect after switching paths. The goal is to minimize interruption and restore service quickly. Network redundancy should be combined with application-level resilience, device registration strategy, and proper monitoring.
Application value in data centers and server rooms
In data centers and server rooms, dual-port redundancy is commonly used on servers, storage systems, firewalls, routers, switches, management controllers, and virtualization hosts. The purpose is to prevent one interface or one access switch from becoming a service interruption point.
Servers may use dual network interface cards for bonding, teaming, or failover. Storage systems may use multiple paths to maintain access to disks or storage networks. Management ports may be separated from service ports so that administrators can still reach equipment even when the service network is under maintenance.
A key advantage is maintenance flexibility. Network equipment may need firmware upgrades, cable replacement, module changes, or switch migration. With redundant connections, one path can often remain active while the other is changed. This supports planned maintenance without complete service shutdown.
However, data center redundancy must be designed at multiple layers. Dual ports alone do not protect against failure of the same access switch, same rack power feed, same aggregation path, or same routing policy. True resilience requires diversity in switches, power, cabling, routing, and sometimes physical location.
Application value in security and monitoring platforms
Security and monitoring systems depend on continuous visibility. Cameras, access control controllers, alarm panels, intrusion detection systems, perimeter devices, and monitoring servers must remain connected to support real-time awareness and event recording. A network interruption may create blind spots.
Dual-port redundancy can help protect important nodes such as central monitoring servers, storage recorders, security gateways, access control controllers, and command terminals. If the main link fails, the backup port can maintain connection to the monitoring network or management platform.
In large facilities, the benefit is not limited to preventing total outage. Redundant ports can also separate video traffic from management traffic, reduce congestion, and keep configuration access available during service network issues. This improves both reliability and maintainability.
For security systems, audit and event records are also important. If a port switchover occurs, the event should be logged. Operators should know whether video loss, alarm delay, or access control interruption was caused by a network path issue. Visibility into redundancy status supports incident review.

Deployment rules that should not be ignored
The first deployment rule is to avoid false redundancy. If both ports are connected to the same switch, same power source, same cable tray, and same upstream route, the system has two local links but not full path diversity. This may still help against a port or cable fault, but it will not protect against switch failure or upstream outage.
The second rule is to match configuration on both paths where service continuity is required. VLANs, IP addressing, gateway access, firewall rules, routing policies, quality settings, and security permissions should be checked on both sides. A backup link that cannot pass required traffic is not a real backup.
The third rule is to define switching behavior. Teams should know which port is primary, which port is backup, how failure is detected, how recovery happens, whether switchover is automatic or manual, and how the system reports the event. Undefined behavior makes troubleshooting difficult.
The fourth rule is to test before relying on it. Redundancy should be verified during commissioning and maintenance. Testing may include disconnecting the primary link, checking alarm reporting, observing traffic recovery, confirming application reconnection, and verifying that the system returns to normal state according to the intended policy.
The fifth rule is to document the design. Port names, cable labels, switch ports, VLANs, IP addresses, redundancy mode, failover rules, and recovery procedures should be recorded. In an emergency, clear documentation helps engineers avoid disconnecting the wrong path or misreading the active state.
Monitoring and maintenance requirements
Dual-port redundancy must be maintained like any other reliability mechanism. If the standby path is never checked, it may fail silently. The system may appear redundant, but when the primary port fails, the backup path may not work because of a disabled switch port, wrong VLAN, expired certificate, cable damage, or changed routing rule.
Monitoring should include link state, error counters, packet loss, port speed, duplex status, switchover events, interface utilization, and device logs. For more advanced systems, heartbeat status, gateway reachability, service-level checks, and application session health may also be monitored.
Maintenance teams should review both ports, not only the active one. It is common for teams to focus on the port carrying traffic while ignoring the backup link. Over time, the standby side may become outdated, disconnected, undocumented, or misconfigured.
Periodic testing should be planned carefully. A redundancy test should not create unnecessary service interruption. It should be scheduled, communicated, and performed with rollback awareness. The goal is to confirm protection, not to create new risk.
Common misunderstandings
One misunderstanding is that two ports always mean high availability. This is not true. A device may have two physical ports, but the second port may be used only for management, diagnostics, bridging, or network separation. High availability depends on supported mode, configuration, topology, and failover behavior.
Another misunderstanding is that redundancy automatically doubles speed. In many active-standby designs, only one port carries traffic at a time. Even in link aggregation, one session may not use the combined bandwidth of both links. Capacity improvement depends on how traffic is distributed.
A third misunderstanding is that the backup path does not need routine attention. In reality, the backup path is useful only if it remains healthy. A neglected standby link can become a hidden failure. Redundancy should be visible, monitored, and periodically verified.
A fourth misunderstanding is that port redundancy can replace full system redundancy. Dual ports protect part of the communication path, but they do not replace redundant power supplies, standby servers, database replication, backup links, disaster recovery, or application-level failover. It is one layer of resilience, not the whole resilience strategy.
How to evaluate whether the design is effective
An effective dual-port design should answer several practical questions. What failure does it protect against? Which port is active during normal operation? What happens if the active link is disconnected? How quickly does traffic recover? Are users affected? Are alarms generated? Can operators see the active path? Can maintenance staff repair the failed path without stopping the service?
The design should also be tested against realistic failure scenarios. Disconnecting a cable is useful, but it may not simulate upstream switch failure, VLAN misconfiguration, gateway loss, routing failure, or service-level timeout. The more critical the system is, the more carefully failure cases should be tested.
Effectiveness can be measured by service continuity, failover time, recovery stability, error rate, operator visibility, and maintenance convenience. A design that switches quickly but causes repeated flapping may not be effective. A design that keeps the link alive but breaks application sessions may need additional tuning.
The best designs are easy to understand during stress. Operators should not need to guess which port is active. Engineers should not need to trace cables blindly. Logs should show what happened. Documentation should match the physical installation. Simplicity and visibility are important parts of reliability.
Final Review
Dual-port redundancy is valuable because it reduces dependence on one physical or logical connection. Its main characteristics include path backup, controlled failover, status visibility, configuration consistency, and the ability to support different working modes such as active-standby, active-active, aggregation, or network separation.
Its application advantages are strongest in environments where interruption is costly, response time matters, or maintenance must be performed without stopping service. Industrial systems, communication platforms, data centers, monitoring networks, and security infrastructures can all benefit from dual-port design when it is properly planned, tested, and maintained.
The key point is that two ports alone do not create reliability. Real value comes from correct topology, path diversity, matching configuration, clear failover rules, regular testing, and continuous monitoring. When these conditions are met, dual-port redundancy becomes a practical and dependable layer of system resilience.
FAQ
Is dual-port redundancy the same as link aggregation?
No. Link aggregation is one possible use of two or more ports, but dual-port redundancy can also use active-standby failover, network separation, or dual uplink paths. Aggregation usually focuses on logical link grouping, while redundancy focuses on continuity when one path fails.
Does a second port always improve bandwidth?
No. In active-standby mode, the backup port may not carry traffic during normal operation. Bandwidth improvement depends on whether the system supports active-active operation or link aggregation and whether the traffic distribution method can actually use both links.
What is the biggest risk in deploying dual-port redundancy?
The biggest risk is false confidence. A system may appear redundant because two cables are connected, but the backup path may not be configured correctly, may share the same failure point, or may never have been tested. Redundancy must be verified, not assumed.
Should the two ports connect to the same switch?
It depends on the target risk. Connecting both ports to the same switch can protect against a local cable or port failure, but it does not protect against switch failure. For stronger resilience, the two ports should connect to different switches or different paths where the system architecture allows it.
How often should the standby path be tested?
The testing interval depends on system importance, maintenance policy, and operating risk. Critical systems should include redundancy checks in regular maintenance plans. Testing should confirm link state, traffic recovery, alarm reporting, application behavior, and documentation accuracy.