

Availability is the ability of a system, service, application, network, or device to remain operational and accessible when users or connected processes need it. In simple terms, availability answers a practical question: can the system be used at the moment it is supposed to be working? If the answer is consistently yes, the system has strong availability. If the system is often offline, unreachable, unstable, or unusable during required operating periods, its availability is weak.
This concept is fundamental across enterprise IT, cloud services, telecom platforms, industrial communications, control environments, and public infrastructure. A platform may have rich features, good performance, and advanced integrations, yet still fail its real purpose if it is unavailable when a business process, operator, customer, or emergency workflow depends on it. For that reason, availability is often treated as one of the most important practical measures of system value.
In modern operations, availability is closely connected to business continuity, service reliability, safety response, and customer trust. A missed call server, unavailable dispatch terminal, offline intercom platform, unreachable business application, or failed industrial communication node can interrupt far more than one technical function. It can delay decisions, disrupt workflows, reduce visibility, and weaken operational resilience. That is why availability is not merely an engineering term. It is a real-world service outcome.
What Is Availability?
Definition and Core Meaning
Availability refers to the proportion of time that a system or service is in a condition where it can perform its intended function. This includes being powered, reachable, stable, responsive enough for its purpose, and operational within the conditions expected by users or dependent systems. A platform may technically be “on” while still not delivering usable availability if it cannot accept calls, process requests, or serve its intended workload properly.
The core meaning of availability is readiness for use. It is not only about whether a device boots or whether software is installed. It is about whether the service can actually be used when needed. In enterprise and communication systems, this often includes server reachability, call control continuity, endpoint registration health, network path stability, and supporting infrastructure such as power and storage.
This is why availability is broader than simple uptime language. Uptime is often part of the picture, but real availability includes the practical ability of the service to do its job under expected conditions.
Availability is not just about whether a system exists. It is about whether that system is usable when the real work begins.
Why Availability Matters
Availability matters because users and operations do not experience technology as architecture diagrams. They experience it as access. If the platform is available, they can log in, place calls, answer intercom requests, monitor activity, send alerts, or continue operations. If it is unavailable, the design quality of the rest of the system becomes much less meaningful in that moment.
In communications and infrastructure environments, the importance becomes even clearer. A business phone server, industrial paging platform, emergency communication node, or monitoring console may not be used constantly every second, but when it is needed, it is often needed immediately. A service that works well most of the time but fails during key moments can create disproportionate operational harm.
This is why availability is often treated as a design requirement from the beginning rather than as a performance improvement added later.

How Availability Works
Availability Depends on Multiple Layers
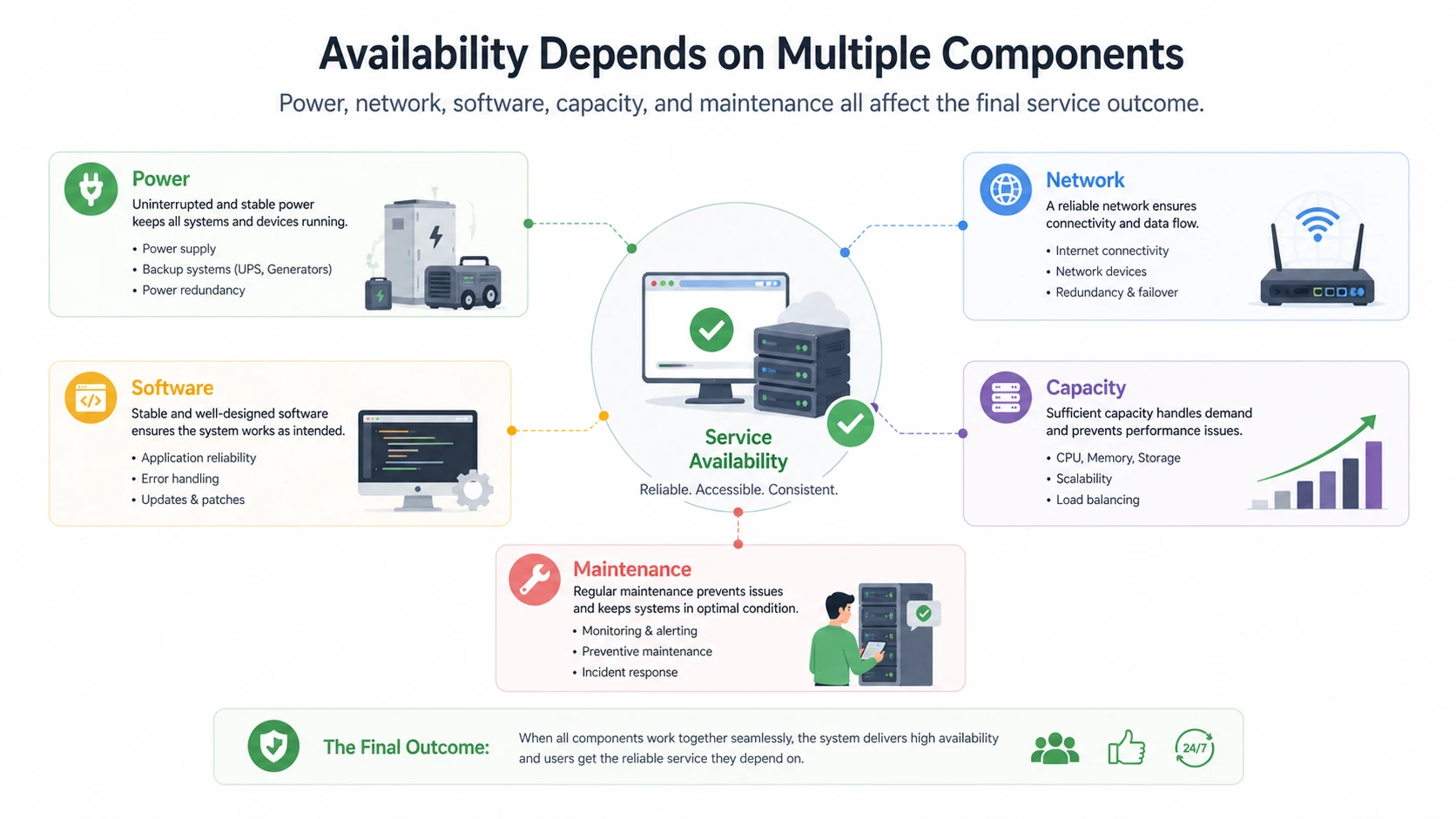
Availability works as the result of many technical layers functioning together successfully. A service may require stable power, healthy servers, working storage, reachable network paths, responsive applications, correct configuration, and available endpoints. If any one of these critical layers fails, overall availability may be reduced even if the rest of the system remains healthy.
This is why availability is often described as an end-to-end property rather than a characteristic of one component alone. A communication platform may have an excellent core server, but if the network path is unstable or the power layer is weak, the user still experiences poor availability. Similarly, a well-designed endpoint may remain online, but if the central service is unreachable, the intended function is still unavailable.
In practical terms, availability emerges from coordination. It depends on whether the whole service chain continues supporting the intended function at the required time.
Monitoring, Recovery, and Service Continuity
Availability is also shaped by how quickly the system can detect trouble and recover from it. No environment is completely free from faults. Hardware fails, software misbehaves, networks fluctuate, and maintenance activities introduce risk. A high-availability design does not assume failure will never happen. Instead, it plans for faults so the service remains accessible or returns quickly with minimal disruption.
This is where monitoring, alarms, failover logic, redundancy, and recovery procedures become important. If a service can detect an issue immediately, shift to a healthy node, restore a failed path, or isolate a problem before users lose access for long, the practical availability can remain strong even under stress. Without these mechanisms, small faults can turn into larger service outages.
Availability therefore depends not only on preventing failure, but on controlling the consequences when failure appears.
Strong availability is rarely the result of never having faults. It is more often the result of detecting, containing, and recovering from faults effectively.
Main Factors That Affect Availability
Power, Network, and Core Infrastructure
One major factor is infrastructure quality. Systems depend on power continuity, network reachability, physical environment, and underlying platform stability. A communication server with excellent software still becomes unavailable if the site loses power, the switch path fails, or upstream routing breaks. In industrial and telecom environments, these infrastructure dependencies are often just as important as the application itself.
This is why resilient design often includes UPS support, dual power options, redundant network links, protected switching layers, and controlled environmental conditions. The goal is to reduce the chance that one infrastructure fault removes service access for everyone at once.
In practice, infrastructure reliability is one of the most common reasons availability rises or falls across real deployments.
Software Stability, Capacity, and Maintenance Discipline
Availability is also affected by software quality, capacity planning, and operational maintenance. If the application becomes unstable under load, if databases become congested, if session handling reaches its limit, or if upgrades are poorly managed, service availability can drop even when the hardware is still online.
Capacity matters because overload can make a technically running system practically unavailable. Users may face timeouts, failed requests, dropped calls, or unusable delays. Maintenance discipline matters because misconfigured updates, expired certificates, neglected storage health, or unreviewed alarms can gradually weaken service continuity until an outage occurs.
For this reason, availability should be managed as an ongoing operational practice, not assumed from installation alone.
How Availability Is Measured
Uptime Percentages and Service Windows
Availability is often expressed as a percentage of time that a system is operational during a defined period. This is where common language such as 99.9% or 99.99% availability comes from. However, the percentage only becomes meaningful when the measurement scope is clear. Does it refer to one application, one site, one service interface, business hours only, or true 24/7 service readiness?
In practical environments, organizations should define the service window carefully. A platform used only during business hours may be measured differently from an emergency communication system expected to be available continuously. A business application may tolerate a short maintenance window more easily than a hospital communication service or industrial alarm-linked platform.
This means availability measurement is not only mathematical. It also depends on operational expectations and service context.
Planned Downtime Versus Unplanned Downtime
Another important measurement issue is the distinction between planned and unplanned downtime. Planned downtime may include scheduled maintenance, upgrades, or controlled service windows. Unplanned downtime usually refers to faults, outages, crashes, or unexpected loss of access. Both influence user experience, but many organizations track them differently for operational analysis.
In critical environments, even planned downtime may need to be minimized carefully. If the service supports safety, dispatching, or high-value operational continuity, the organization may aim for maintenance approaches that preserve service access rather than simply turning the platform off. This is one reason redundancy and failover design are so closely tied to availability targets.
Availability measurement becomes most useful when it reflects the real experience of the users who depend on the service.
Benefits of High Availability
Better Business Continuity
One of the clearest benefits of high availability is business continuity. When systems remain accessible, work can continue with less interruption. Staff can communicate, operators can monitor, customers can access services, and management can make decisions without sudden blind spots or delays caused by unavailable platforms.
This continuity matters in almost every industry, but especially in environments where communication and coordination are central. If a platform remains available during peak periods, infrastructure events, or organizational growth, the business experiences fewer disruptions and less operational uncertainty.
In this sense, availability supports not only technical stability, but organizational stability.
Lower Operational Risk and Better User Trust
High availability also reduces operational risk. A system that remains accessible is less likely to create secondary failures such as missed alerts, delayed escalation, failed transactions, frustrated customers, or unplanned manual workarounds. Many service problems grow more serious simply because the right platform was unavailable at the wrong moment.
User trust improves as well. Teams are more willing to rely on platforms that consistently work when needed. Customers trust services that remain reachable. Operators trust control systems that do not disappear during stressful situations. In communications infrastructure, this trust is essential because users often do not test a system constantly; they judge it most strongly when they suddenly need it.
That is why availability is closely linked to confidence, not just to engineering statistics.
High availability creates value not only by preventing outages, but by making people more willing to depend on the system in the first place.
Additional Operational Benefits
More Predictable Maintenance and Planning
Availability-focused design often improves maintenance planning because resilient systems can tolerate controlled service activities more gracefully. When redundancy, failover, and service segmentation are present, organizations can perform updates, inspections, or replacements with lower risk of total interruption. This makes maintenance more predictable and less disruptive.
Predictability matters because emergency repair is usually more expensive and more stressful than planned maintenance. A system designed for better availability helps shift the operating model away from reactive outage response and toward structured lifecycle management.
In practical terms, strong availability often supports better discipline across the whole support organization.
Better Alignment With Critical Workflows
Another benefit is alignment with workflows that cannot pause easily. Hospitals, control rooms, dispatch centers, transport networks, industrial sites, and enterprise communication environments often depend on systems that must remain usable through ordinary workload, abnormal events, and business expansion. Availability helps those platforms stay aligned with the urgency and continuity of the real work they support.
This is especially important when communications infrastructure is tied to voice service, intercom response, paging, emergency escalation, or remote coordination. In those cases, the cost of unavailability is not measured only in inconvenience. It can also be measured in slower response and reduced operational awareness.
Availability therefore becomes a practical support condition for critical workflow quality.
Maintenance Tips for Availability
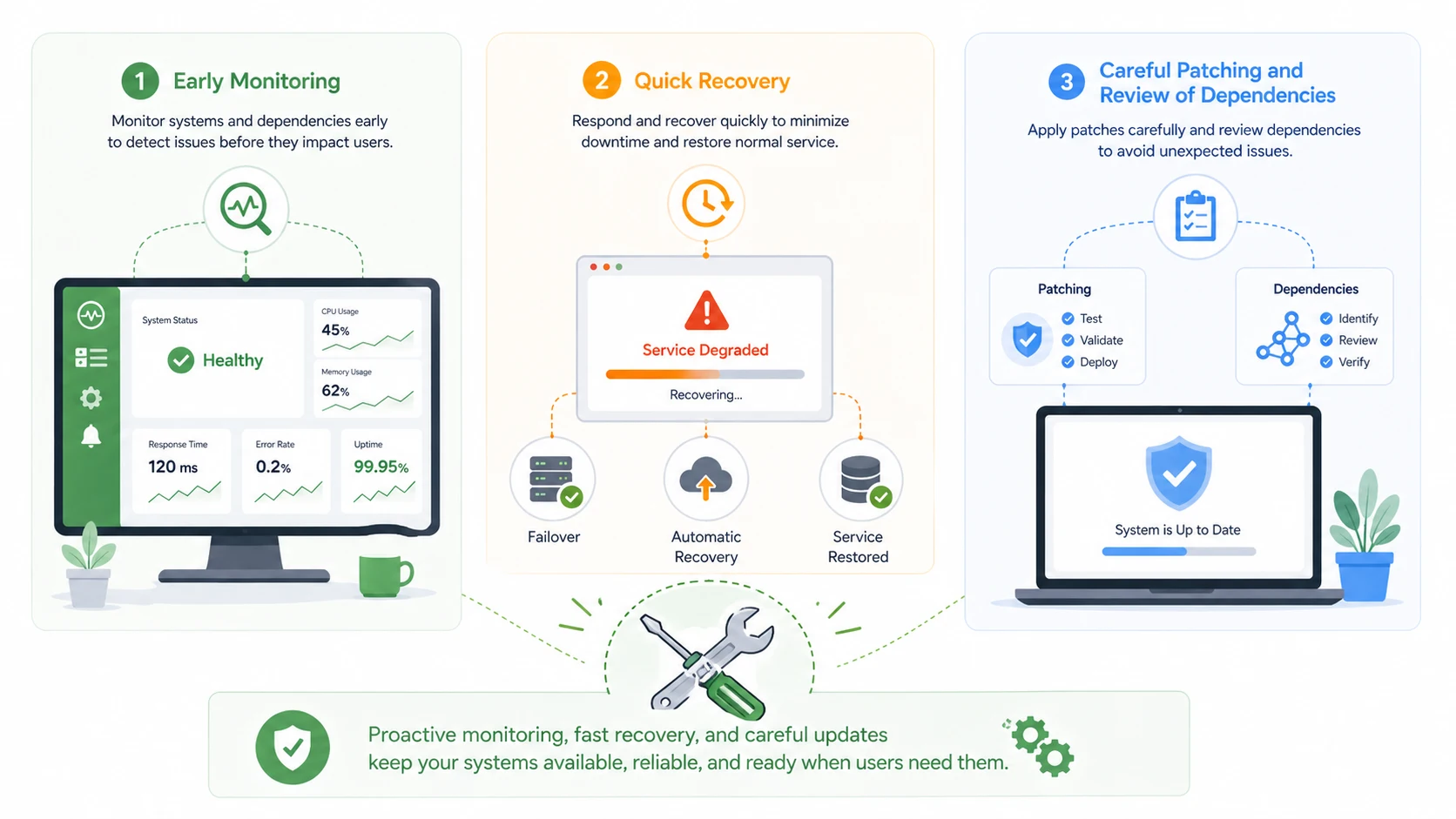
Monitor Early and Restore Fast
One of the most important maintenance practices is early detection. Teams should monitor power events, server health, CPU load, storage behavior, network latency, registration status, alarm conditions, and application response time before users begin reporting visible failure. When issues are detected early, they can often be corrected while the service is still functioning or before the outage spreads.
Fast restoration is just as important. Availability is shaped not only by whether faults occur, but by how long they affect service. Clear escalation paths, incident response discipline, spare parts readiness, backup procedures, and tested recovery steps all help reduce outage duration when problems appear.
Availability management therefore depends on operational readiness as much as on system design.
Patch Carefully and Review Dependencies
Maintenance teams should also manage changes carefully. Software patches, certificate renewals, firmware updates, database tuning, and network changes can all improve availability in the long run, yet they can also reduce it if handled without discipline. Poor change control is a common reason that otherwise healthy systems become unavailable unexpectedly.
Dependencies also deserve regular review. A service may depend on DNS, authentication services, gateways, storage, upstream trunks, external APIs, or monitoring systems. If these dependencies are not documented and checked, availability assumptions may be overly optimistic. A platform can look healthy until one hidden dependency fails.
Good maintenance means treating availability as an ecosystem property, not a single-device characteristic.
Best Practices for Improving Availability
Reduce Single Points of Failure
One of the strongest availability practices is to reduce single points of failure wherever practical. This may include redundant power, dual network paths, clustered servers, backup trunks, distributed nodes, replicated storage, and resilient gateway design. If one component can fail without taking down the entire service, the system has a better chance of remaining available.
The exact redundancy pattern depends on the environment, but the principle is widely applicable. A communication platform that depends on one server, one switch, one power source, and one route is much more fragile than one designed with alternatives at critical points.
Availability improves when no single ordinary failure becomes an automatic full service loss.
Design Around Real Operating Needs
Another best practice is to match availability design to actual operating requirements. Not every system needs the same level of resilience, and not every service justifies the same cost or complexity. A basic internal tool may tolerate short planned downtime. A dispatch platform, industrial communication service, or emergency help-point system may require much stronger availability planning.
This means organizations should define what “available” really means for each system. Is the service needed only in office hours, or continuously? Does it support routine communication only, or also urgent escalation? Does a five-minute outage matter, or does it create operational exposure? These questions help shape realistic availability design instead of generic overbuilding or underprotection.
Good availability strategy begins with service purpose, not with fashionable architecture alone.
Availability becomes most valuable when it is engineered to match the urgency, risk, and continuity expectations of the real service it supports.
Applications of Availability
Business Systems, Cloud Services, and IT Platforms
Availability is essential in business software, cloud platforms, data services, collaboration tools, remote access services, and identity systems because users depend on these platforms throughout the working day. If they become unreachable, productivity drops quickly and support pressure rises. In customer-facing services, the impact may also include revenue loss or reduced trust.
Cloud and enterprise environments place special emphasis on availability because services are often shared across many users and workflows. One outage can affect a whole department, branch structure, or customer segment at once. This is why availability planning is central to serious platform design in modern IT operations.
In these environments, availability is closely tied to service-level expectations, customer experience, and operational confidence.
Telecom, Unified Communications, and Industrial Communication Systems
Availability is equally important in telecom and communication systems. IP PBX platforms, SIP servers, dispatch consoles, intercom networks, paging services, gateways, and unified communication environments all need to remain accessible when users and operations depend on them. A system that is unavailable during busy periods, incidents, or shift changes can affect much more than one user session.
Becke Telcom has gained significant experience from previous implementations in campuses, factories, tunnels, transportation facilities, business parks, etc. Availability is of utmost importance as it directly affects the feasibility and sustainability of the project. Moreover, enterprise and industrial communication systems typically not only support voice calls but also support intercom responses, paging, help point access, remote coordination, and cross-environment operational communication. As the scale and importance of these functions continue to expand, a well-designed platform should remain available continuously.
This is particularly valuable in campuses, factories, tunnels, transport facilities, business parks, and critical infrastructure sites where communication continuity supports both operations and response discipline.
Availability in Modern Communication Projects
From Office Calling to Multi-Role Service Continuity
Modern communication projects rarely stop at basic calling alone. Organizations increasingly want one platform to support desk phones, mobile clients, SIP trunks, paging, intercom endpoints, remote branches, and operational workflows together. As these roles expand, availability becomes more important because more functions now depend on the same communication backbone.
A failure in this type of environment can affect internal coordination, external calling, field response, help-point communication, and administrative visibility at the same time. That is why availability planning should be built into the architecture from the beginning rather than added only after the system becomes larger and more essential.
Communication availability is strongest when it is treated as a service design principle rather than as a repair objective after outages appear.
Supporting Emergency and Operational Awareness
In some environments, communication availability directly influences situational awareness and response speed. If an intercom platform is unavailable, a help request may not reach the operator. If a paging service fails, instructions may not be delivered. If a server outage interrupts a dispatch interface, coordination may slow during exactly the moment it is most needed.
This is one reason why availability matters deeply in industrial and infrastructure communication design. The goal is not only convenience or feature access. It is maintaining the continuity of communication functions that support safety, escalation, and coordinated action.
In these contexts, availability becomes part of operational resilience itself.
Conclusion
Availability is the practical ability of a system or service to remain accessible and operational when users or processes need it. It is one of the most important qualities in IT, telecom, cloud, and industrial communication environments because even well-designed systems lose value quickly if they cannot be used at the right time.
It works through the health of many connected layers, including power, network, applications, servers, capacity, monitoring, and recovery processes. Its benefits include stronger business continuity, reduced operational risk, better user trust, and improved alignment with services that cannot easily pause.
For organizations building communication platforms, enterprise services, or industrial systems, availability is not just a technical metric. It is a practical measure of whether the system can support the real work it was meant to serve.
FAQ
What is availability in simple terms?
In simple terms, availability means a system is working and usable when people or connected processes need it. If the platform remains accessible at the right time, it has good availability.
If it is often offline, unreachable, or unusable, its availability is weak.
What is the difference between availability and uptime?
Uptime usually refers to how long a system has been running, while availability focuses on whether the service is actually accessible and usable. A system may be technically running but still provide poor availability if users cannot reach it or use it properly.
That is why availability is usually the more practical service measure.
Why is availability important in communication systems?
Availability is important in communication systems because users often need voice, paging, intercom, or dispatch functions immediately when business or operational events occur. If the communication platform is unavailable, coordination and response can be delayed.
Strong availability helps communication services remain dependable during both routine activity and urgent situations.







