In modern IP-based communication systems, the concept of direct global addressability has gradually been replaced by layered routing architectures that separate internal network identity from external visibility. Network Address Translation (NAT) is one of the most critical mechanisms enabling this separation. It operates at the intersection of routing, session tracking, and transport-layer manipulation, allowing multiple internal devices to communicate with external networks through a controlled and state-aware translation boundary.
Rather than functioning as a simple IP substitution tool, NAT behaves as a dynamic decision system embedded inside edge gateways. Every packet entering or leaving a protected network is evaluated, transformed, and tracked based on real-time session state. This introduces a controlled asymmetry between internal and external addressing domains, which fundamentally reshapes how modern IP networks scale and operate.
Separation of internal addressing and external routing domains
The first structural principle behind NAT is the separation of private and public addressing spaces. Internal networks typically rely on RFC1918 address ranges, which are intentionally non-routable on the global internet. These addresses are reusable across different organizations, which eliminates global uniqueness but introduces isolation from external routing tables.
When a device inside such a network initiates communication, its private IP address has no meaning outside its local domain. NAT bridges this gap by converting internal source addresses into globally valid external addresses at the network boundary. This process allows private networks to operate independently of public IP allocation constraints while still maintaining full connectivity.
This separation also introduces a structural advantage: internal network topology remains invisible to external observers. As a result, NAT indirectly contributes to reducing direct exposure of internal infrastructure, although it is not a security mechanism by design.
Stateful packet transformation mechanism at network edges
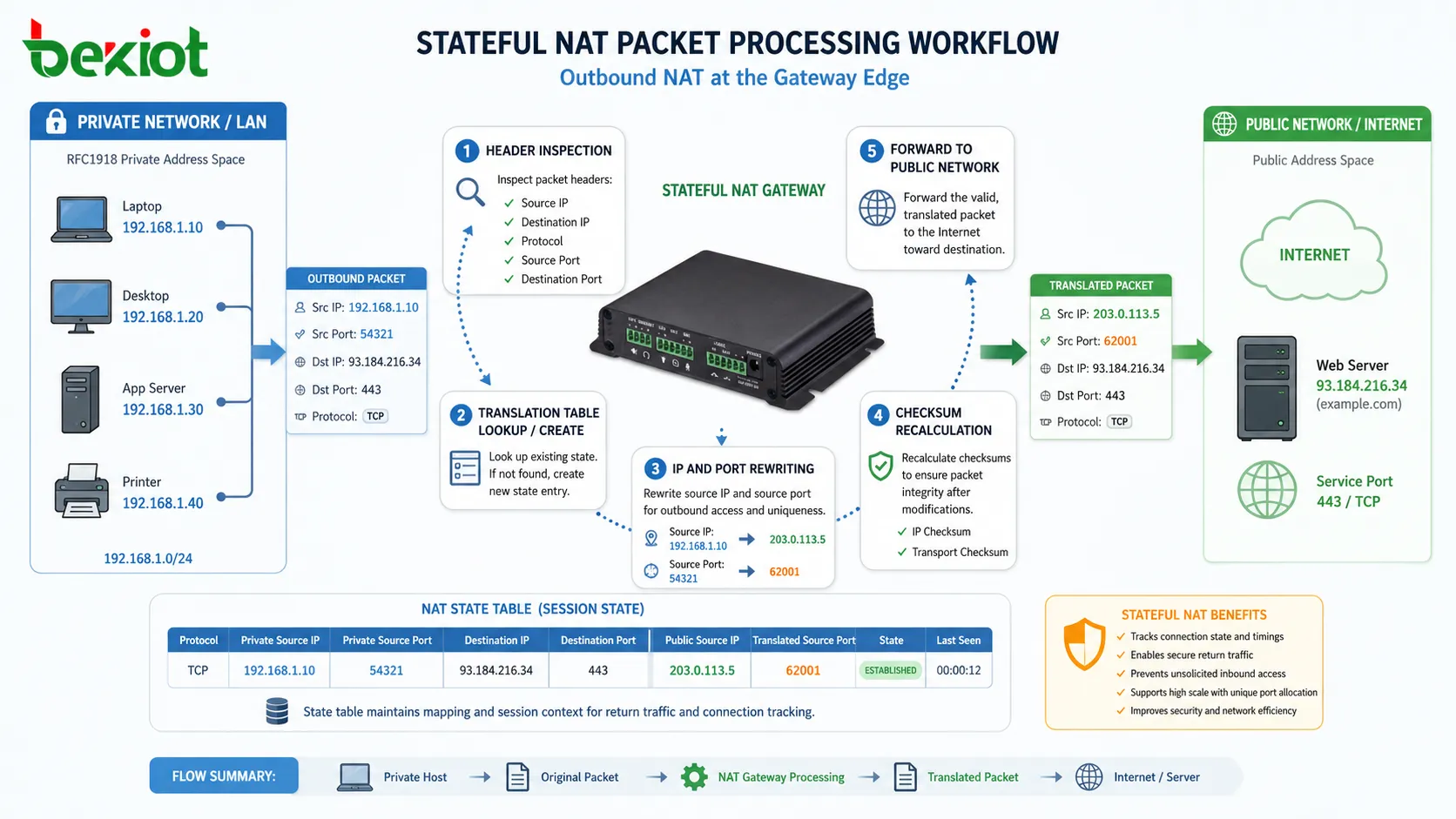
At the core of NAT operation is a stateful packet processing engine located within a gateway device such as a router, firewall, or dedicated NAT appliance. When an outbound packet arrives, the device inspects multiple header fields including source IP address, destination IP address, protocol type, and transport-layer port numbers.
Based on this inspection, the system generates or retrieves a translation entry from its internal state table. The source IP address is then replaced with a public-facing IP address, and in most modern implementations, the source port is also rewritten to ensure uniqueness across concurrent sessions.
This transformation must also preserve packet integrity. After modifying header fields, checksum recalculations are performed at both IP and transport layers to ensure that the packet remains valid within downstream routing systems.
Construction and lifecycle of translation state tables
A fundamental component of NAT operation is the translation state table, which maintains mappings between internal sessions and external representations. Each active communication flow generates a unique entry that binds internal addressing information to translated external identifiers.
A typical NAT entry includes internal IP address, internal source port, translated public IP, assigned external port, protocol type, and session timeout metadata. This structured mapping ensures that return traffic can be accurately routed back to the originating internal host.
The lifecycle of these entries is tightly controlled. When a session is initiated, a new mapping is created. During active communication, the entry is refreshed based on traffic activity. When the session becomes idle or is explicitly closed, the entry is removed to free system resources.
| Field | Function |
|---|---|
| Internal IP | Source device identity within private network |
| External IP | Public representation used for internet routing |
| Port Mapping | Enables multiplexing of multiple sessions on a single IP |
| Protocol Identifier | Distinguishes TCP, UDP, or ICMP flows |
| Timeout Policy | Controls session expiration and resource cleanup |
Port Address Translation and connection multiplexing behavior
One of the most widely deployed forms of NAT is Port Address Translation (PAT), also known as NAT overload. In this model, multiple internal devices share a single public IP address. Differentiation between sessions is achieved through dynamic allocation of source port numbers.
When multiple internal hosts initiate outbound connections simultaneously, the NAT system assigns unique external port identifiers to each session. This ensures that return traffic can be correctly mapped back to the appropriate internal endpoint without ambiguity.
This mechanism significantly improves IPv4 address efficiency. Instead of requiring one public IP per device, thousands of devices can operate concurrently using a single externally visible address pool.
Return traffic reconstruction and reverse mapping logic
Inbound traffic processing in NAT is fundamentally symmetric to outbound translation but relies entirely on lookup-based reconstruction. When a response packet arrives from an external server, the NAT gateway examines the destination IP and port combination.
It then performs a lookup in the translation state table to identify the corresponding internal mapping entry. Once found, the system restores the original destination IP and port before forwarding the packet to the internal network.
This reverse mapping process ensures full session continuity. Neither external servers nor internal clients are aware of the translation layer, which remains transparent at the application level.
Timeout control and resource optimization strategy
Because NAT is fundamentally a stateful system, it must manage memory and processing resources efficiently. Each active session consumes a portion of the translation table, and uncontrolled growth can lead to performance degradation or table exhaustion.
To mitigate this, NAT implementations apply protocol-specific timeout policies. TCP sessions are typically maintained until explicit termination signals are received, while UDP sessions rely on inactivity-based expiration timers. ICMP mappings are generally short-lived due to their stateless nature.
Carrier-grade translation architecture in large-scale networks
In large-scale service provider networks, traditional NAT implementations are no longer sufficient due to the massive number of concurrent subscribers. Carrier-Grade NAT (CGNAT) extends the basic NAT model into a distributed, high-capacity translation architecture capable of handling millions of simultaneous sessions.
Unlike enterprise NAT, which typically operates at a single edge gateway, CGNAT systems distribute translation workloads across clustered nodes. Each node is responsible for a portion of the address pool and session table, enabling horizontal scalability and fault tolerance. This architecture is essential in mobile networks, broadband ISPs, and large content delivery environments where IPv4 exhaustion is most severe.
In CGNAT deployments, session persistence and deterministic mapping become more complex due to load balancing between translation nodes. To address this, deterministic NAT algorithms or subscriber-based hashing mechanisms are used to ensure that sessions from the same internal host consistently map to the same external translation context.
Impact on real-time communication systems and transport protocols
Network Address Translation introduces unique challenges for real-time communication systems such as VoIP, video conferencing, and industrial dispatch networks. These systems rely heavily on end-to-end connectivity and often embed IP addressing information directly into application payloads.
Protocols such as SIP (Session Initiation Protocol) and H.323 may experience connectivity issues when NAT modifies transport-layer addressing. This is because session negotiation messages may contain private IP references that are invalid in external networks.
To mitigate this, NAT traversal techniques such as STUN (Session Traversal Utilities for NAT), TURN (Traversal Using Relays around NAT), and ICE (Interactive Connectivity Establishment) are commonly deployed. These mechanisms allow endpoints to discover their public-facing addresses and establish media paths across NAT boundaries.
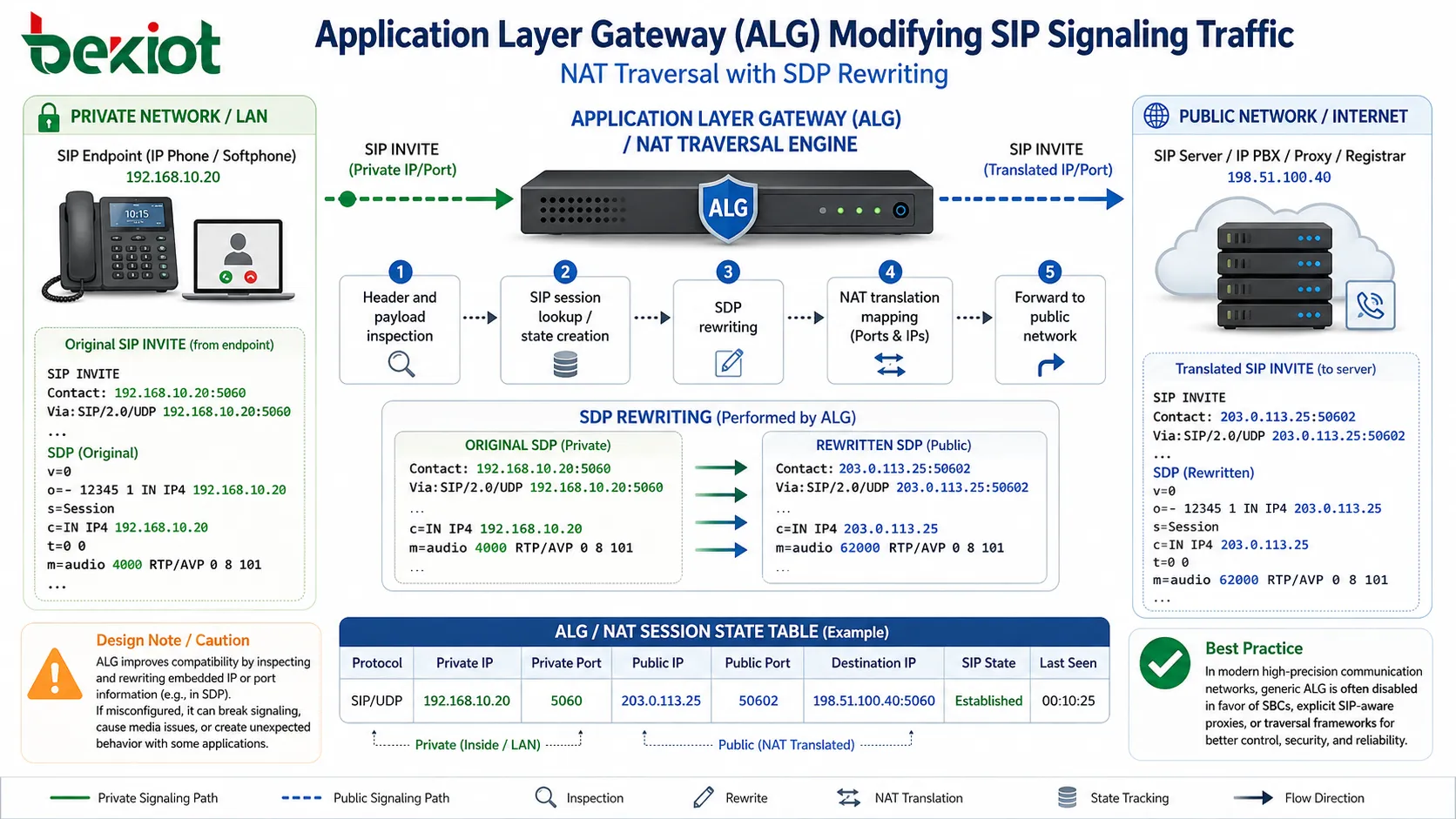
Application Layer Gateway behavior and protocol adaptation
Some NAT implementations include Application Layer Gateway (ALG) functionality, which inspects and modifies application-layer payloads to maintain protocol consistency. This is particularly important for protocols that embed IP address or port information inside the payload itself.
For example, SIP ALG can rewrite embedded SDP (Session Description Protocol) fields to replace private IP addresses with translated public addresses. While this improves compatibility, it can also introduce complexity and unintended side effects if improperly configured.
Modern network designs often disable generic ALG features in favor of explicit application-aware proxies or traversal frameworks, especially in high-precision communication environments.
IPv6 transition and the diminishing role of NAT
The introduction of IPv6 significantly changes the long-term role of NAT in global networking architecture. With an expanded address space, IPv6 eliminates the need for address conservation strategies such as PAT.
However, NAT has not disappeared. Instead, it has evolved into transitional mechanisms such as NAT64 and dual-stack translation systems that enable interoperability between IPv4 and IPv6 networks.
In many real-world deployments, IPv4 and IPv6 coexist, requiring translation layers that bridge fundamentally different addressing models. This transitional phase ensures backward compatibility while enabling gradual migration to IPv6-native infrastructures.
Performance constraints and high-throughput optimization models
NAT processing introduces computational overhead due to packet inspection, header rewriting, and state table management. In high-throughput environments, this can become a bottleneck if not properly optimized.
To address performance constraints, modern NAT implementations leverage hardware acceleration, multi-core processing, and distributed session tables. Network processors (NPUs) and ASIC-based forwarding engines are commonly used to offload translation tasks from general-purpose CPUs.
Another optimization technique involves flow caching, where frequently used translation entries are stored in high-speed memory to reduce lookup latency during packet processing.
Failure modes and diagnostic behavior in NAT systems
When NAT systems encounter resource exhaustion or configuration inconsistencies, several failure modes may occur. The most common issue is port exhaustion, where no available external ports remain for new session allocation.
Another frequent failure scenario is asymmetric routing, where return traffic bypasses the NAT device due to incorrect routing configuration, leading to broken session state and dropped packets.
Diagnostic analysis typically involves inspecting translation tables, session logs, and interface counters to identify anomalies in mapping behavior or resource utilization.
Operational deployment strategies in enterprise environments
In enterprise networks, NAT deployment is typically aligned with security zoning and segmentation strategies. Internal networks are divided into trust zones, and NAT gateways are placed at controlled boundaries between internal and external domains.
Policy-based NAT rules may be applied to different traffic classes, enabling selective translation based on application type, destination, or user group. This allows organizations to maintain granular control over outbound and inbound communication flows.
In industrial communication systems, NAT is often combined with VPN tunneling and firewall policies to enforce multi-layer network isolation while preserving operational connectivity.
Relationship between NAT and industrial communication architectures
In industrial environments such as dispatch centers, power systems, transportation hubs, and emergency communication networks, NAT plays a critical role in enabling multi-site connectivity across private IP domains.
These systems often rely on hybrid architectures where local control networks operate independently while still requiring centralized coordination. NAT enables this by abstracting internal addressing while maintaining controlled communication paths between distributed nodes.
However, strict latency and reliability requirements in such systems often necessitate careful NAT configuration to avoid jitter, session loss, or delayed signaling propagation.
System-level interpretation of NAT behavior
From a system engineering perspective, NAT can be interpreted as a deterministic state machine that transforms packet identity based on predefined rules and dynamic session context.
It operates across multiple abstraction layers: network addressing, transport multiplexing, session persistence, and policy enforcement. This multi-layer behavior distinguishes NAT from simple routing mechanisms and positions it as a foundational component of modern IP network architecture.
FAQ
Why does NAT still exist in IPv6 environments?
Although IPv6 reduces the need for address translation, NAT still exists in transitional mechanisms that bridge IPv4 and IPv6 networks, ensuring backward compatibility.
Can NAT affect latency in high-frequency communication systems?
Yes. Additional processing for header rewriting and state lookup can introduce minor latency, especially under high session load conditions.
What is the difference between NAT and a firewall?
NAT modifies addressing information for routing purposes, while a firewall enforces security policies. They often coexist but serve different functional roles.
Why do some applications fail behind NAT?
Applications that embed IP information inside payload data or require direct peer-to-peer connectivity may fail unless NAT traversal techniques are applied.
Is CGNAT reversible for troubleshooting?
CGNAT systems maintain logging and mapping records, but due to large-scale aggregation, reverse tracing requires centralized logging correlation systems.