Hot standby is a high-availability design in which a backup device, server, controller, gateway, or platform remains powered on, synchronized, and ready to take over when the active unit fails. Instead of waiting for manual repair or cold restart, the standby side can assume service responsibility through automatic failover, helping reduce downtime and maintain continuity for critical systems.
This function is used in communication platforms, data centers, industrial control systems, security systems, power infrastructure, transportation networks, cloud services, telecom gateways, emergency systems, and enterprise applications. Its core value is not simply having a spare machine. The standby unit must be connected, monitored, synchronized, and tested so that it can become active when the production node is no longer available.
From Backup Device to Service Continuity Design
A traditional backup may sit unused until a failure occurs. Hot standby is different because the backup element is already part of the live architecture. It listens to heartbeat signals, receives configuration updates, tracks service status, and prepares to take over with minimal interruption.
For users, the ideal result is simple: calls continue, sessions recover, alarms remain visible, control systems stay available, and operators do not need to rebuild the service manually. Behind that simple experience, the architecture must handle data synchronization, IP takeover, service state, routing updates, fault detection, and recovery order.
In business and industrial environments, high availability is often more important than maximum performance. A system that is slightly slower but continuously available may be more valuable than a powerful system that fails without protection.
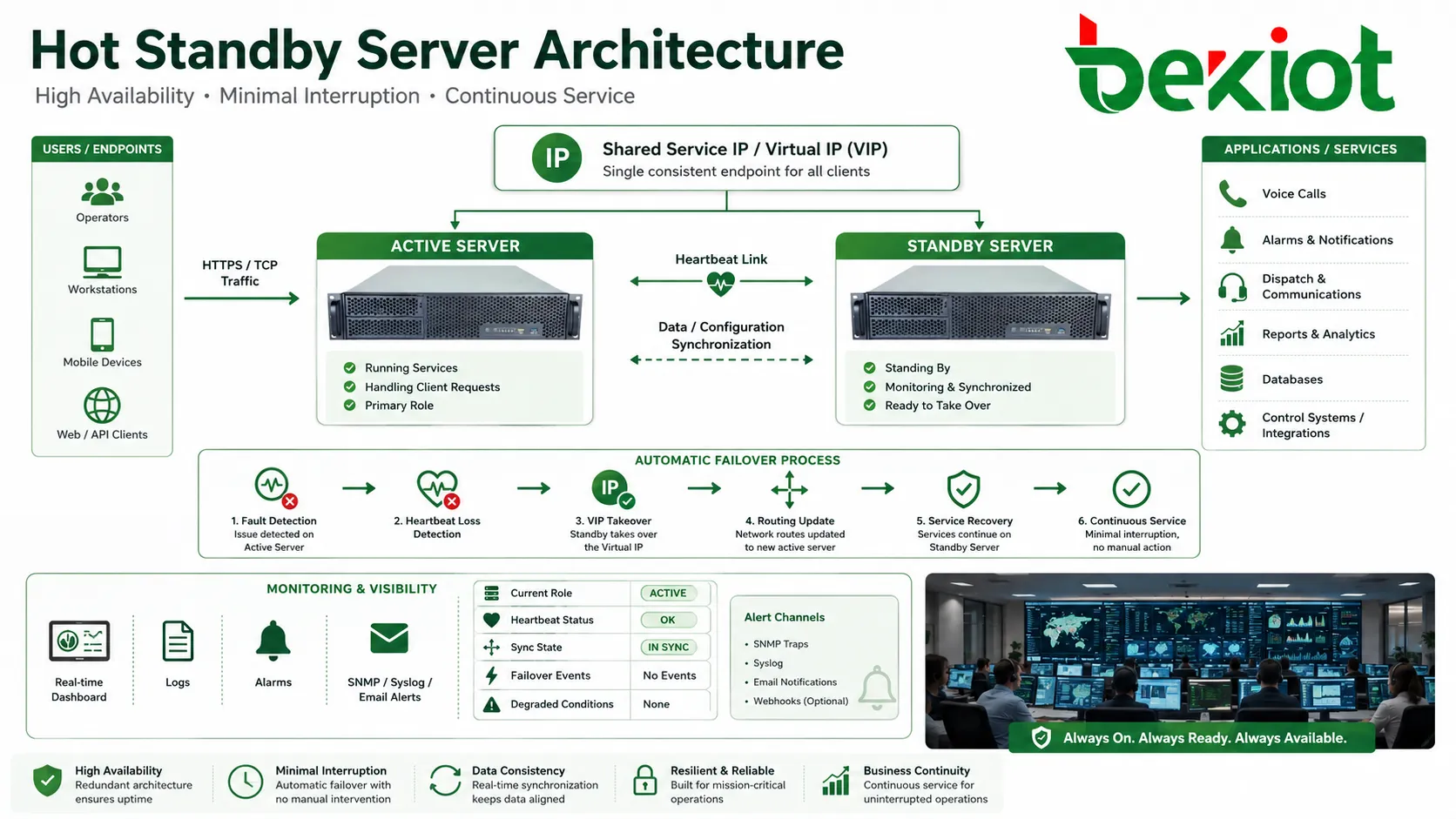
How the Takeover Process Works
Heartbeat Detection
The active and standby nodes usually exchange heartbeat signals. These signals confirm that each side is alive and that the primary node is still responsible for service. Heartbeat traffic may run over a dedicated cable, management network, private VLAN, or redundant network path.
If the standby node stops receiving valid heartbeat messages within a defined time window, it may suspect that the active node has failed. The system then begins failover logic. This logic must be carefully designed because reacting too quickly to a temporary network delay can create false failover.
State Synchronization
For a smooth transition, the standby side needs current information. This may include configuration files, user data, routing tables, session records, call states, alarm status, database entries, license state, device registration information, or control logic.
Some systems synchronize only configuration, while others synchronize real-time service state. The deeper the synchronization, the smoother the failover can be. However, real-time synchronization also increases complexity and network dependency.
Failure Decision
After detecting a possible fault, the system must decide whether the active node is truly unavailable. This may involve checking heartbeat loss, service process status, disk state, interface state, database response, CPU load, power alarms, or external monitoring input.
A good design avoids single-condition decisions. For example, losing one heartbeat link should not automatically trigger takeover if another management path still confirms that the active node is healthy.
Role Switching
When failover is confirmed, the standby node changes its role and becomes active. It may take over a virtual IP address, start service processes, advertise routes, register to peer systems, activate trunks, assume database master role, or begin processing calls and alarms.
The former active node may be isolated, rebooted, repaired, or later returned as the standby node. Rejoin behavior should be controlled to prevent service conflict.
Key Architecture Models
Active-Standby Pair
The most common design uses one active node and one standby node. The active side handles production service, while the standby side waits and synchronizes. When the active side fails, the standby side takes over.
This model is relatively easy to understand and is widely used in PBX systems, firewalls, routers, controllers, databases, storage appliances, and industrial platforms. Its limitation is that the standby resource may remain underused during normal operation.
Dual Active with Standby Logic
Some environments use both nodes actively but still provide failover between them. Each side may handle part of the workload under normal conditions, and one side may absorb more traffic when the other side fails.
This design improves resource utilization but requires more careful load balancing, synchronization, session handling, and capacity planning. If each node normally runs near full load, it may not have enough reserve capacity during failure.
Cluster-Based Redundancy
Large systems may use a cluster rather than a simple two-node pair. Multiple nodes share services, monitor each other, and redistribute workloads when one member fails.
Cluster designs can provide better scalability and resilience, but they are more complex to deploy and maintain. They require stronger coordination, quorum control, health checks, and consistent configuration management.
Geographically Separated Protection
Some critical systems place standby resources in another building, campus, data center, or region. This protects against local power loss, fire, flooding, network room failure, or site-level disruption.
Geographic protection improves disaster resilience, but it introduces latency, data consistency, network routing, and operational coordination challenges. Not every service can fail over smoothly across long distances.
| Model | Best Fit | Main Design Concern |
|---|---|---|
| Active-Standby | Simple high-availability pairs for servers, gateways, PBX platforms, and controllers. | Standby resource utilization and failover timing. |
| Dual Active | Systems that need load sharing and redundancy at the same time. | Capacity reserve, session distribution, and failback control. |
| Cluster | Large platforms with multiple service nodes and scalable workloads. | Quorum, synchronization, split-brain prevention, and operational complexity. |
| Remote Site Protection | Disaster recovery and site-level resilience. | Latency, data consistency, network routing, and recovery procedure. |
Network Elements That Decide Reliability
Heartbeat Path
The heartbeat link should be reliable and preferably redundant. If heartbeat traffic uses the same unstable network as ordinary service traffic, the standby node may misjudge service state during congestion or switch failure.
For critical deployments, designers often use two heartbeat paths, separate physical links, or different switch paths. This reduces the chance that one network fault creates an incorrect takeover.
Virtual Service Address
Many systems use a virtual IP address or floating service address. Users and peer systems connect to this stable address rather than to the physical address of one node. During failover, the address moves to the standby side.
This method simplifies client configuration, but network devices must update ARP, routing, DNS, or session tables quickly enough. Slow address update can make failover appear delayed even after the standby node is active.
Shared or Replicated Data
Some systems rely on shared storage. Others replicate data between nodes. Shared storage simplifies consistency but can become a single point of failure if not protected. Replication improves independence but requires careful handling of delay, conflict, and incomplete writes.
The right method depends on whether the system needs configuration continuity, transaction consistency, recording integrity, session preservation, or simple service restart.
Routing and Trunk Behavior
Communication systems may connect to SIP trunks, radio gateways, PSTN gateways, dispatch consoles, external APIs, monitoring platforms, and remote endpoints. These external systems must know where to send traffic after failover.
If the standby node becomes active but trunks, routes, or peer registrations do not update, users may still experience service interruption. Failover testing should include upstream and downstream systems, not only the two local nodes.
Management and Monitoring Layer
High availability should be visible to administrators. Dashboards, logs, alarms, SNMP traps, syslog, email alerts, or monitoring platforms should show current role, heartbeat status, synchronization state, failover events, and degraded conditions.
Without monitoring, a system may silently run on the standby side for weeks. If another failure then occurs, there may be no remaining protection.
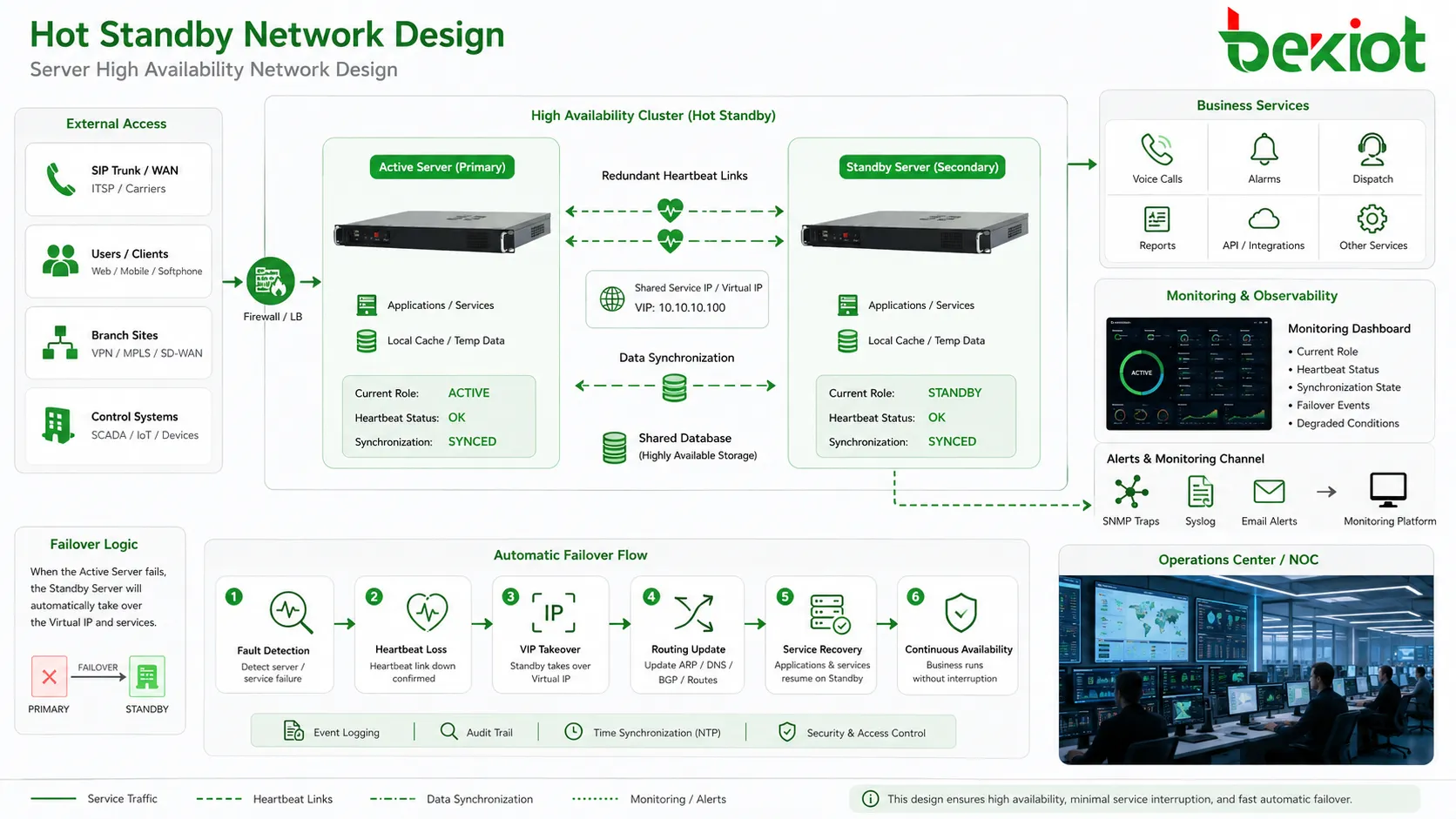
Important Technical Features
Automatic Failover
Automatic failover allows the standby side to become active without waiting for manual intervention. This is essential when the system supports real-time communication, safety alarms, control operations, or customer-facing service.
The failover threshold should be tuned carefully. If it is too sensitive, false failover may occur. If it is too slow, users may experience unnecessary downtime.
Manual Switchover
Manual switchover allows administrators to move service from one node to another during maintenance, upgrades, testing, or planned repair. This is useful when replacing hardware, applying patches, or validating standby readiness.
A controlled switchover is safer than waiting for an unplanned failure because teams can schedule the action, monitor the result, and roll back if needed.
Failback Control
After the original active node is repaired, the system must decide whether service should move back automatically or remain on the current active node until a planned window. Automatic failback may restore the original design quickly, but it can also create another service interruption.
Many critical systems prefer manual failback so operators can verify health, synchronization, and traffic status before moving service again.
Split-Brain Prevention
Split-brain occurs when both nodes believe they are active at the same time. This can cause duplicate services, database conflict, call routing errors, IP address conflict, or data corruption.
Prevention methods may include quorum mechanisms, witness nodes, fencing, priority rules, redundant heartbeat links, and strict role control. Split-brain protection is one of the most important parts of any high-availability design.
Data Integrity Protection
During failover, the system must protect configuration and operational data. This may include database transactions, call records, alarm logs, device registration state, recordings, and event history.
Data integrity is especially important when the system supports compliance, billing, emergency records, dispatch logs, or audit trails.
Where This Design Is Used
Enterprise Communication Platforms
PBX servers, SIP platforms, voicemail systems, recording servers, contact center systems, and unified communication platforms can use standby protection to maintain business calling. If the active server fails, the backup side can continue processing registrations, calls, routing rules, and service logic.
In critical communication projects, Becke Telcom applies high-availability thinking to communication system planning, helping customers consider server redundancy, gateway continuity, dispatch availability, and failover paths as part of the overall solution design.
Industrial Control and SCADA
Industrial systems often use standby controllers, redundant SCADA servers, dual communication gateways, and backup operator stations. These systems support production, safety, energy, utilities, and process monitoring.
Failover should be tested under real process conditions. A control system that switches roles correctly in a lab may behave differently when connected to field devices, PLCs, historians, alarms, and operator consoles.
Security and Surveillance Systems
Video management servers, access control platforms, alarm servers, storage nodes, and control room systems may require standby protection to avoid blind spots or security response delays.
In these environments, the failover design should consider live video, recording continuity, door control, alarm acknowledgment, event logs, and operator permissions.
Data Center and Cloud Services
Servers, databases, firewalls, load balancers, storage arrays, routers, and application platforms often use high-availability architecture. Standby protection may exist at the hardware, virtualization, container, database, or application layer.
The more layers involved, the more important it is to define which layer is responsible for failover. Multiple independent failover mechanisms can conflict if not planned carefully.

Public Safety and Transportation
Emergency response centers, railway systems, tunnel control rooms, airport operation systems, port command centers, and traffic management platforms require high service availability. Communication failure can delay response, reduce situational awareness, or interrupt coordination.
For these systems, redundancy should cover not only servers but also power, network switches, trunks, endpoints, operator stations, and external interfaces.
Deployment Benefits Beyond Downtime Reduction
The most obvious benefit is service continuity. When the primary node fails, users can continue working with less interruption. This is important for systems that support voice communication, alarms, monitoring, data access, and control functions.
Another benefit is planned maintenance flexibility. Administrators can move service to the standby side, maintain the original node, and then restore the normal role after verification. This reduces the need for long service windows.
Standby design also improves confidence in system upgrades. If an update causes a problem on one side, the organization may have a controlled path to recover service, provided the architecture and rollback plan were designed correctly.
For management teams, high availability supports risk control. It turns a single device failure from a full outage into a managed event that can be investigated and repaired with less business disruption.
Practical Failure Scenarios
Hardware Failure
A server, power supply, disk, interface card, gateway, or controller may fail. The standby node should detect that the active service is no longer healthy and take over according to the configured policy.
Hardware failure is often the easiest scenario to understand, but not always the most common cause of service interruption.
Application Process Crash
The machine may still be powered on while the service application has stopped responding. A good health check should detect not only whether the server is alive but also whether the service itself is working.
Checking only ping response is usually not enough. The system may answer ping while the call engine, database, alarm process, or web service has failed.
Network Isolation
A node may become isolated from users but still believe it is healthy. This is dangerous because the system may not know which side should be active.
Redundant network paths and quorum logic help avoid incorrect decisions during isolation events.
Database Corruption
If data becomes corrupted on the active side and corruption is replicated immediately to the standby side, redundancy alone may not solve the problem. Backup and versioned recovery are still needed.
High availability is not the same as backup. A standby node protects service continuity, while backup protects historical recovery.
Operator Error
Incorrect configuration, accidental deletion, wrong routing, or failed upgrade can affect both active and standby nodes if configuration is synchronized automatically.
Change control, approval workflow, configuration export, and rollback plans are essential for reducing human-error impact.
High availability reduces downtime from component failure, but it does not replace backup, cybersecurity, change control, monitoring, or disciplined maintenance.
Testing and Acceptance Strategy
Failover should be tested before production handover. A test should confirm that the standby side can detect failure, assume service, update network paths, restore external connections, preserve required data, and generate appropriate alarms.
Tests should include planned switchover, active node shutdown, service process failure, network link failure, power failure where safe, and recovery after repair. Each test should define expected behavior and maximum acceptable interruption.
Acceptance records should include failover time, data consistency result, service availability result, alarm records, log evidence, operator confirmation, and any unresolved issues. Without records, the system may appear redundant but remain unproven.
Operation and Maintenance Guidelines
Monitor the standby state continuously. A standby node that is powered on but out of synchronization is not ready. Administrators should watch heartbeat status, replication lag, resource usage, service status, license validity, storage capacity, and software version consistency.
Keep both sides updated carefully. Version mismatch can cause failover failure or unexpected behavior. However, updates should be staged and tested so that a faulty upgrade does not break both nodes at once.
Perform periodic switchover drills. A system that has never been tested under controlled conditions may not work during a real failure. Regular drills also help operators understand the procedure and response time.
Review logs after every failover. Even if service appears normal, the cause should be investigated. Repeated failover events may indicate network instability, resource overload, hardware degradation, or poor health-check thresholds.
FAQ
Is hot standby the same as backup?
No. A standby node is used for service continuity, while backup is used for data recovery. A system usually needs both because failover cannot recover old versions of corrupted or deleted data.
How fast should failover happen?
The acceptable time depends on the application. Voice, control, alarms, and public safety systems usually need faster recovery than ordinary reporting or archive systems.
Can a standby system protect against software bugs?
Only sometimes. If the same bug exists on both nodes, failover may not solve the issue. Version control, testing, rollback, and backup remain important.
What causes split-brain conditions?
Split-brain is often caused by heartbeat loss, network isolation, weak quorum design, or incorrect failover rules. It happens when more than one node believes it should be active.
What should be checked after a failover event?
Check active role, standby health, synchronization status, service logs, user impact, data integrity, external trunk or interface status, alarm records, and the root cause of the failover.